How Dat Works
Dat is a protocol for sharing data between computers. Dat’s strengths are that data is hosted and distributed by many computers on the network, that it can work offline or with poor connectivity, that the original uploader can add or modify data while keeping a full history and that it can handle large amounts of data.
Dat is compelling because the people working on it have a dedication to user experience and ease-of-use. The software around Dat brings publishing within reach for people with a wide range of skills, not just technical. Although first designed with scientific data in mind, the Dat community is testing the waters and has begun to use it for websites, art, music releases, peer-to-peer chat programs and many other experiments.
This guide is an in-depth tour through the bits and bytes of the Dat protocol, starting from a blank slate and ending with being able to download and share files with other peers running Dat. There will be enough detail for readers who are considering writing their own implementation of Dat, but if you are just curious how it works or want to learn from Dat’s design then I hope you will find this guide useful too!
URLs
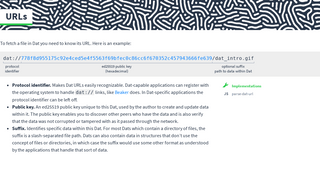
To fetch a file in Dat you need to know its URL. Here is an example:
- Protocol identifier. Makes Dat URLs easily recognizable. Dat-capable applications can register with the operating system to handle
dat://links, like Beaker does. In Dat-specific applications the protocol identifier can be left off. - Public key. An ed25519 public key unique to this Dat, used by the author to create and update data within it. The public key enables you to discover other peers who have the data and verify that the data was not corrupted or tampered with as it passed through the network.
- Suffix. Identifies specific data within this Dat. For most Dats which contain a directory of files, the suffix is a slash-separated file path. Dats can also contain data in structures that don’t use the concept of files or directories, in which case the suffix would use some other format as understood by the applications that handle that sort of data.
Discovery
Dat clients use several different methods for discovering peers who they can download data from. Each discovery method has strengths and weaknesses, but combined they form a reasonably robust way of finding peers.
Discovery keys
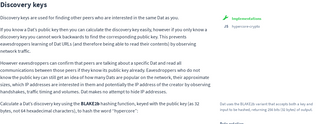
Discovery keys are used for finding other peers who are interested in the same Dat as you.
If you know a Dat’s public key then you can calculate the discovery key easily, however if you only know a discovery key you cannot work backwards to find the corresponding public key. This prevents eavesdroppers learning of Dat URLs (and therefore being able to read their contents) by observing network traffic.
However eavesdroppers can confirm that peers are talking about a specific Dat and read all communications between those peers if they know its public key already. Eavesdroppers who do not know the public key can still get an idea of how many Dats are popular on the network, their approximate sizes, which IP addresses are interested in them and potentially the IP address of the creator by observing handshakes, traffic timing and volumes. Dat makes no attempt to hide IP addresses.
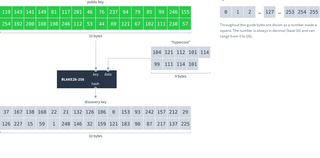
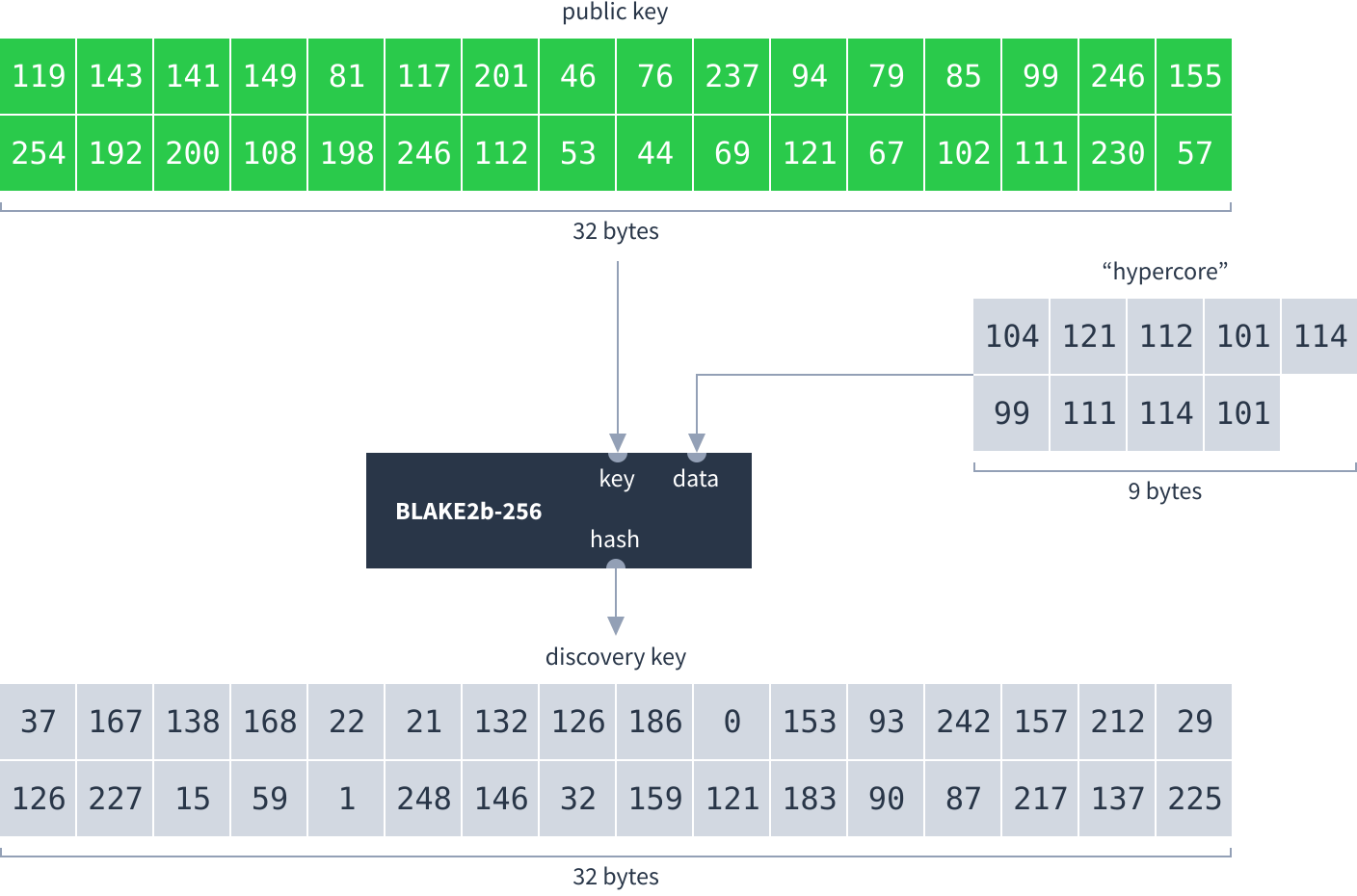
Calculate a Dat’s discovery key using the BLAKE2b hashing function, keyed with the public key (as 32 bytes, not 64 hexadecimal characters), to hash the word “hypercore”:
Local network discovery
Peers broadcast which Dats they are interested in via their local network.
- Strengths. Fast, finds physically nearby peers, doesn’t need special infrastructure, works offline.
- Weaknesses. Limited reach.
- Deployment status. Currently in use, will be replaced by Hyperswarm in the future.
Local network discovery uses multicast DNS, which is like a regular DNS query except instead of sending queries to a nameserver they are broadcast to the local network with the hope that someone else on the network sees it and responds.
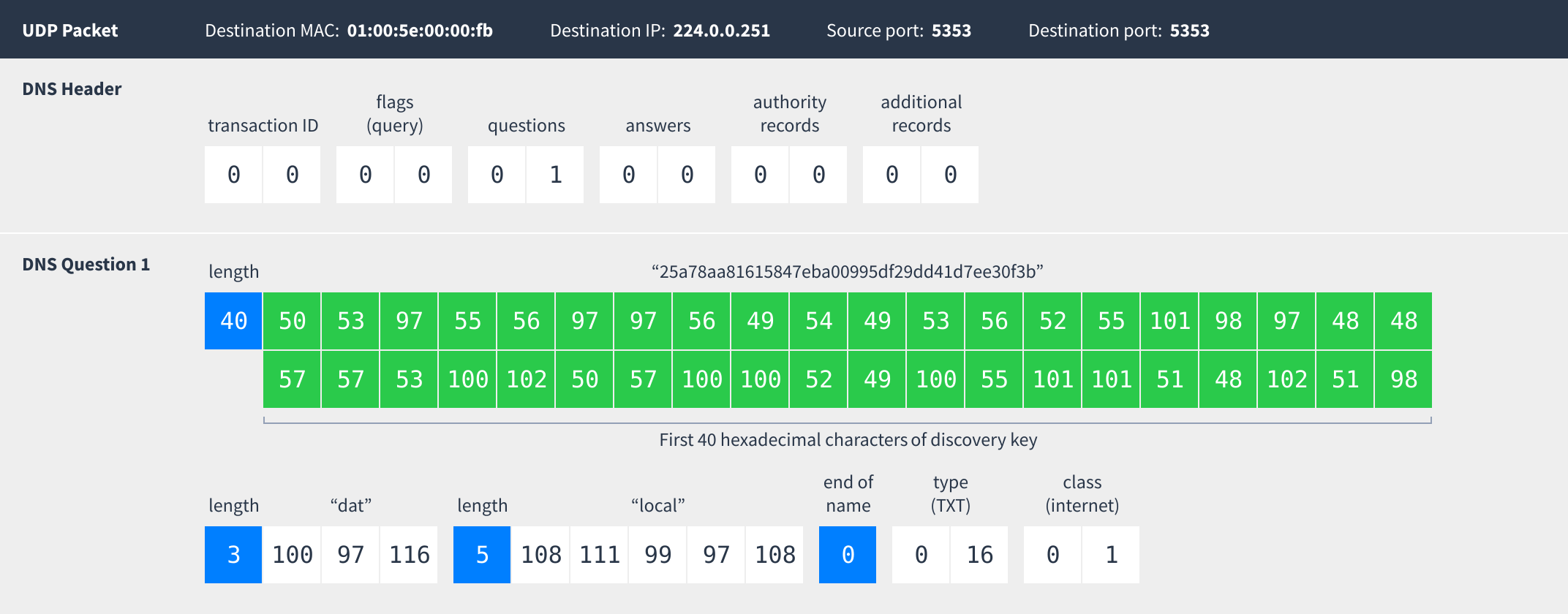
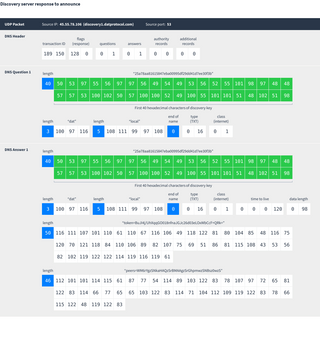
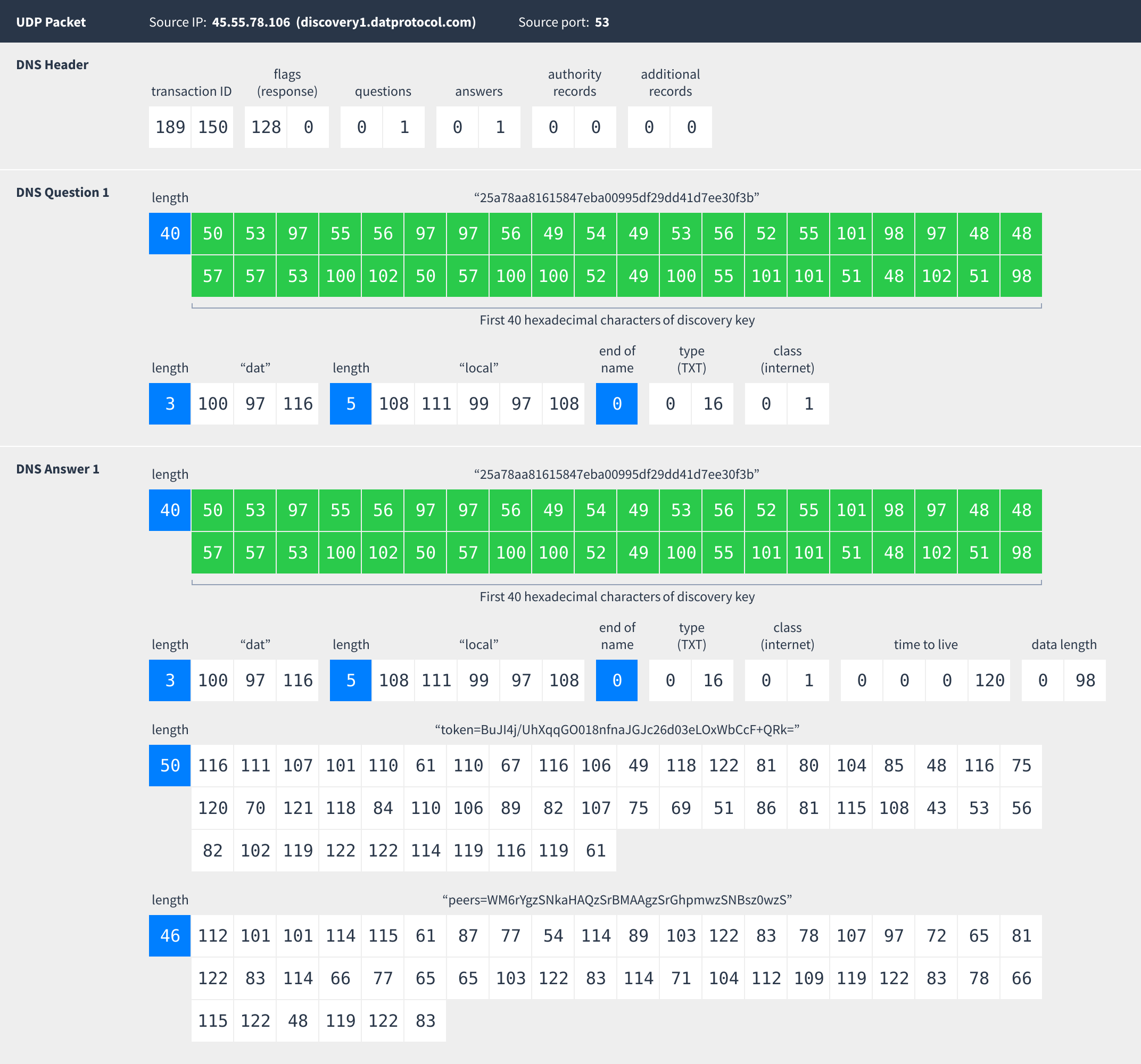
Multicast DNS packets are sent to the special broadcast MAC and IP addresses shown above. Both the source and destination ports are 5353.
Essentially the computer is asking “Does anybody have any TXT records for the domain name 25a78aa81615847eba00995df29dd41d7ee30f3b.dat.local?” Other Dat clients on the network will recognize requests following this pattern and know that the client who sent it is looking for peers.
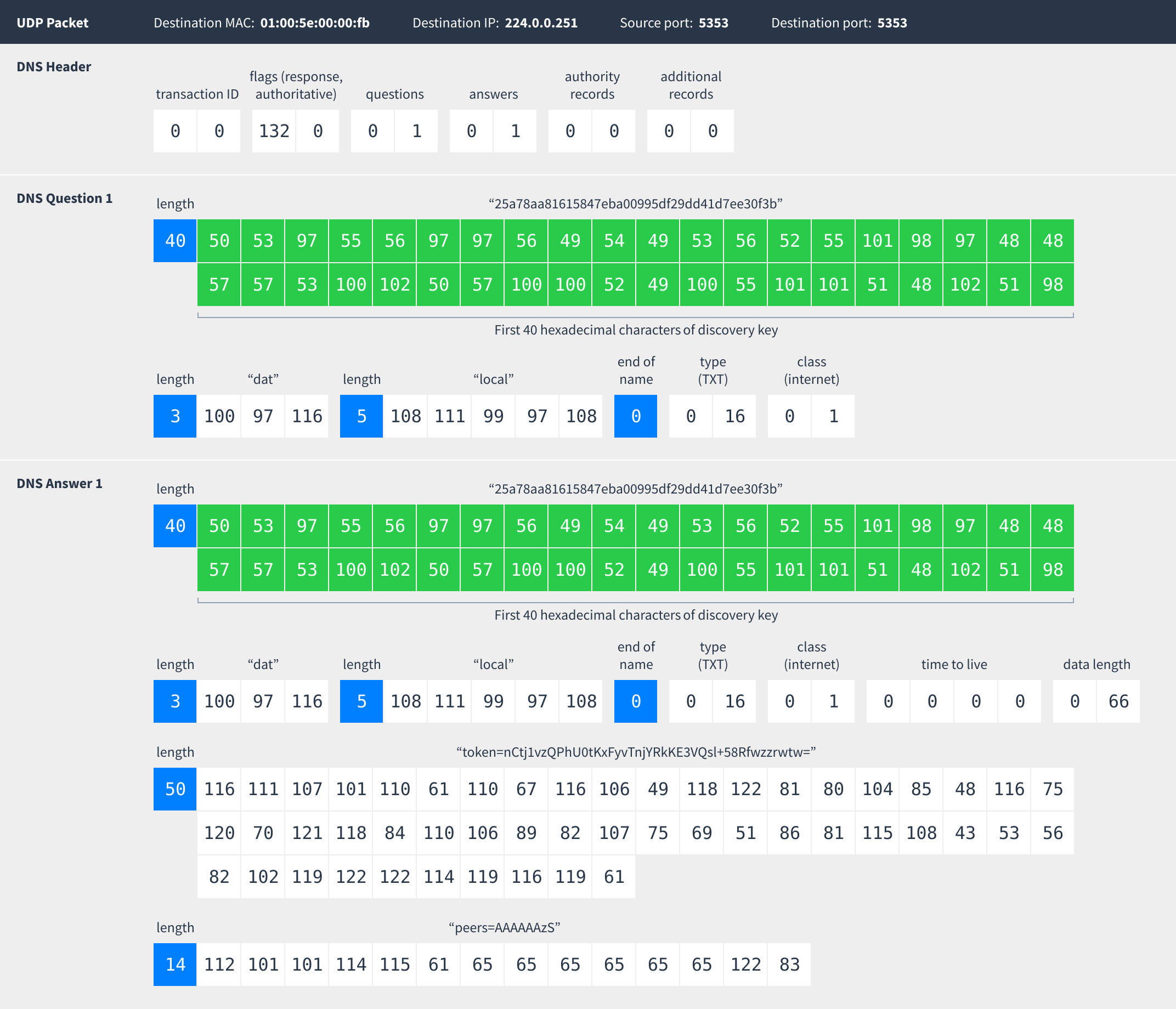
Responses contain two TXT records:
- The token record is a random value that makes it easier for clients to avoid connecting to themselves. If a client sees a response with the same token as a response they just sent out, they will know it came from them and ignore it.
- The peers record is a base64-encoded list of IP addresses and ports of peers interested in this Dat:
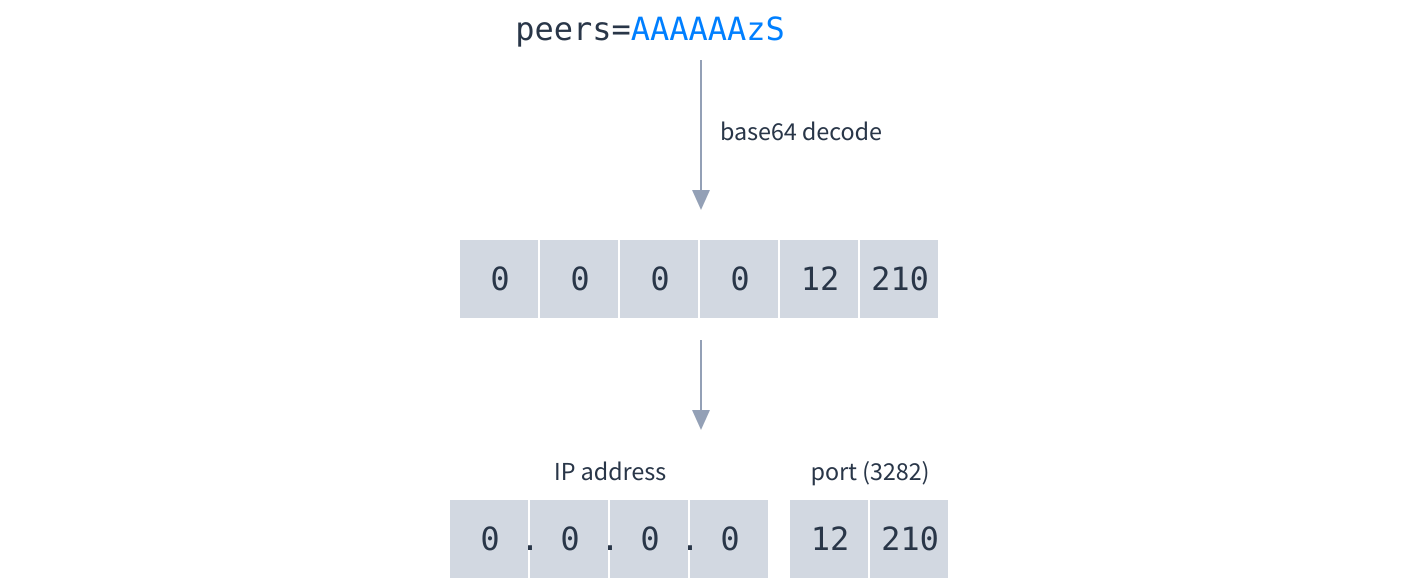
The special IP address 0.0.0.0 means “use the address this mDNS response came from”. When discovering peers on the local network all mDNS responses will contain only one peer and will use the 0.0.0.0 address.
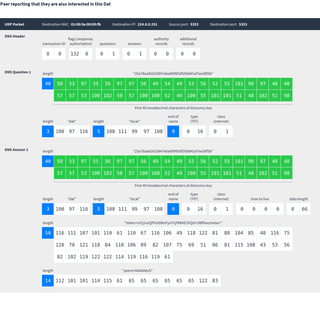
Centralized DNS discovery
Peers ask a server on the internet for other peers using a DNS-based protocol.
- Strengths. Fast, global reach.
- Weaknesses. Must be online, centralized point of failure, one server sees everyone’s metadata.
- Deployment status. Currently in use, will be replaced by Hyperswarm in the future.
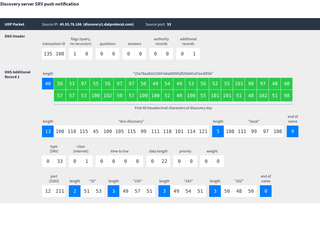
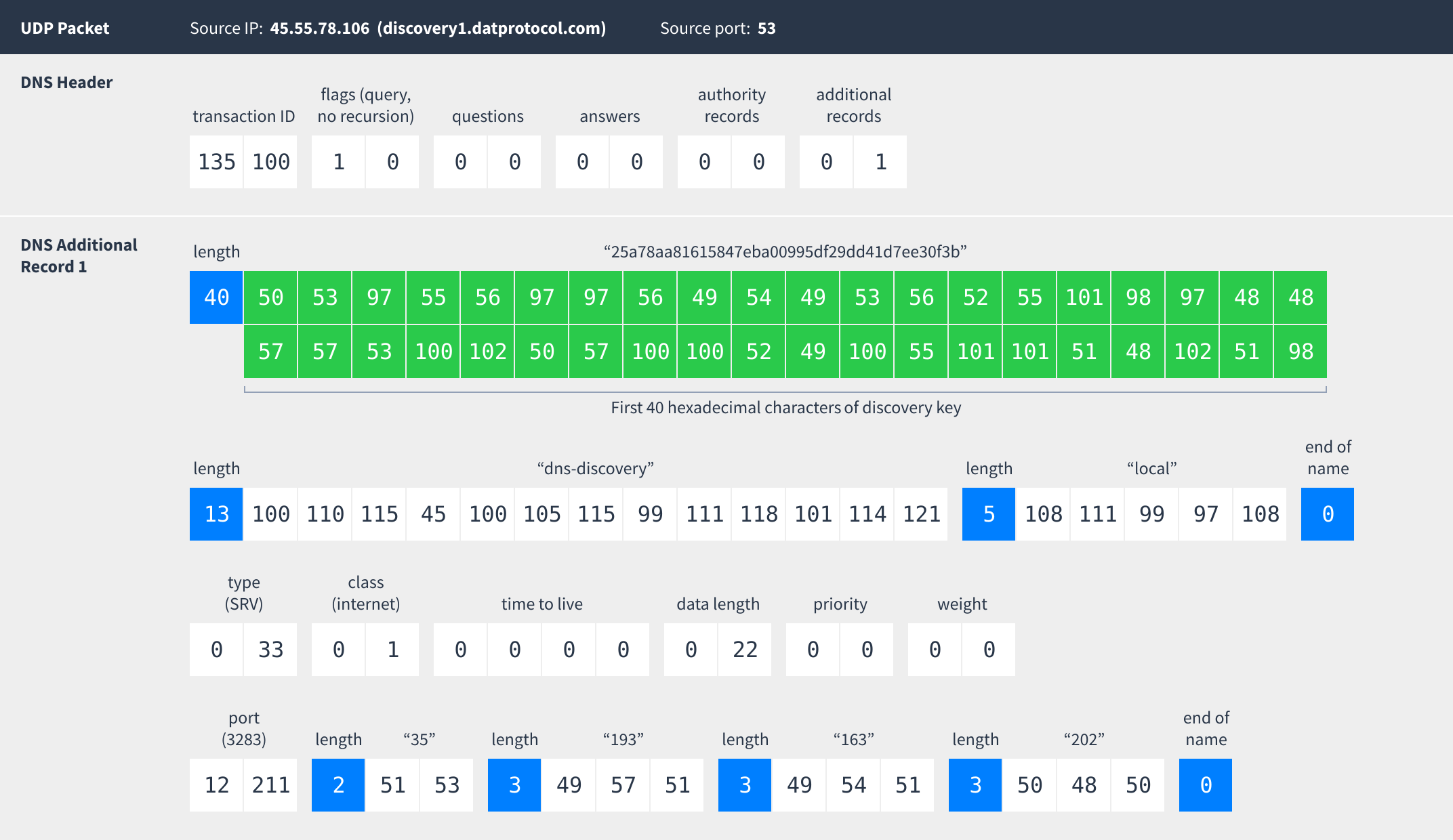
Currently the server running this is discovery1.datprotocol.com. If that goes offline then discovery2.datprotocol.com can be used as a fallback.
Here is a typical message flow between a Dat peer and the DNS discovery server:
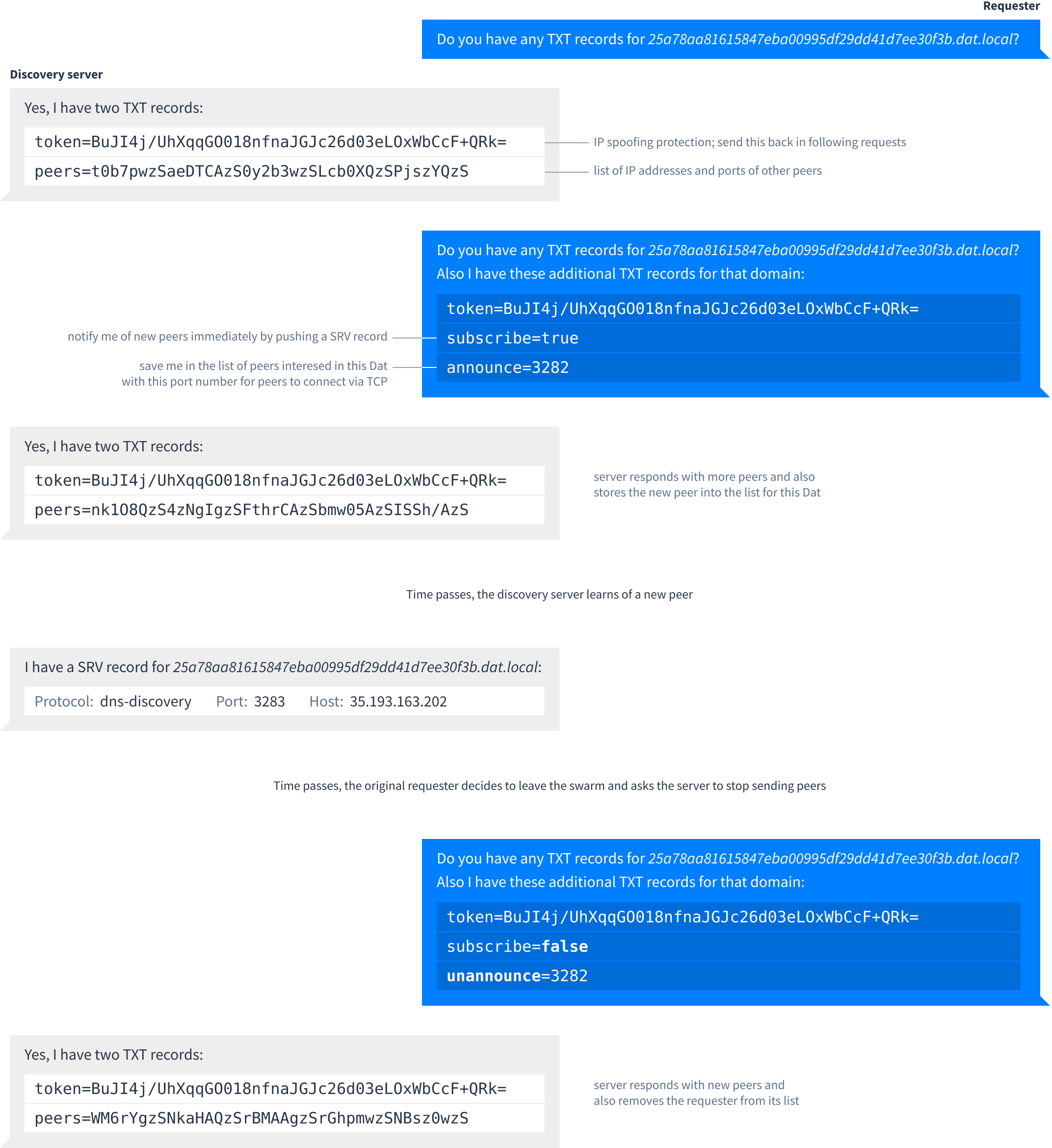
To stay subscribed, peers should re-announce themselves every 60 seconds. The discovery server will also cycle its tokens periodically so peers should remember the token they last received and update it when they receive a new one.
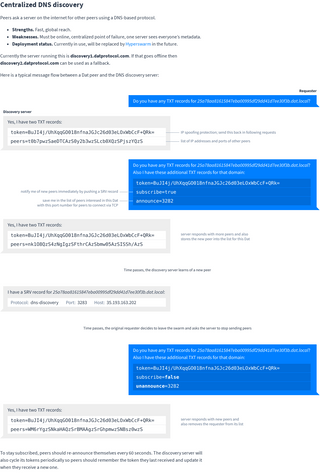
The peers record returned by the discovery server uses the same structure as in mDNS:
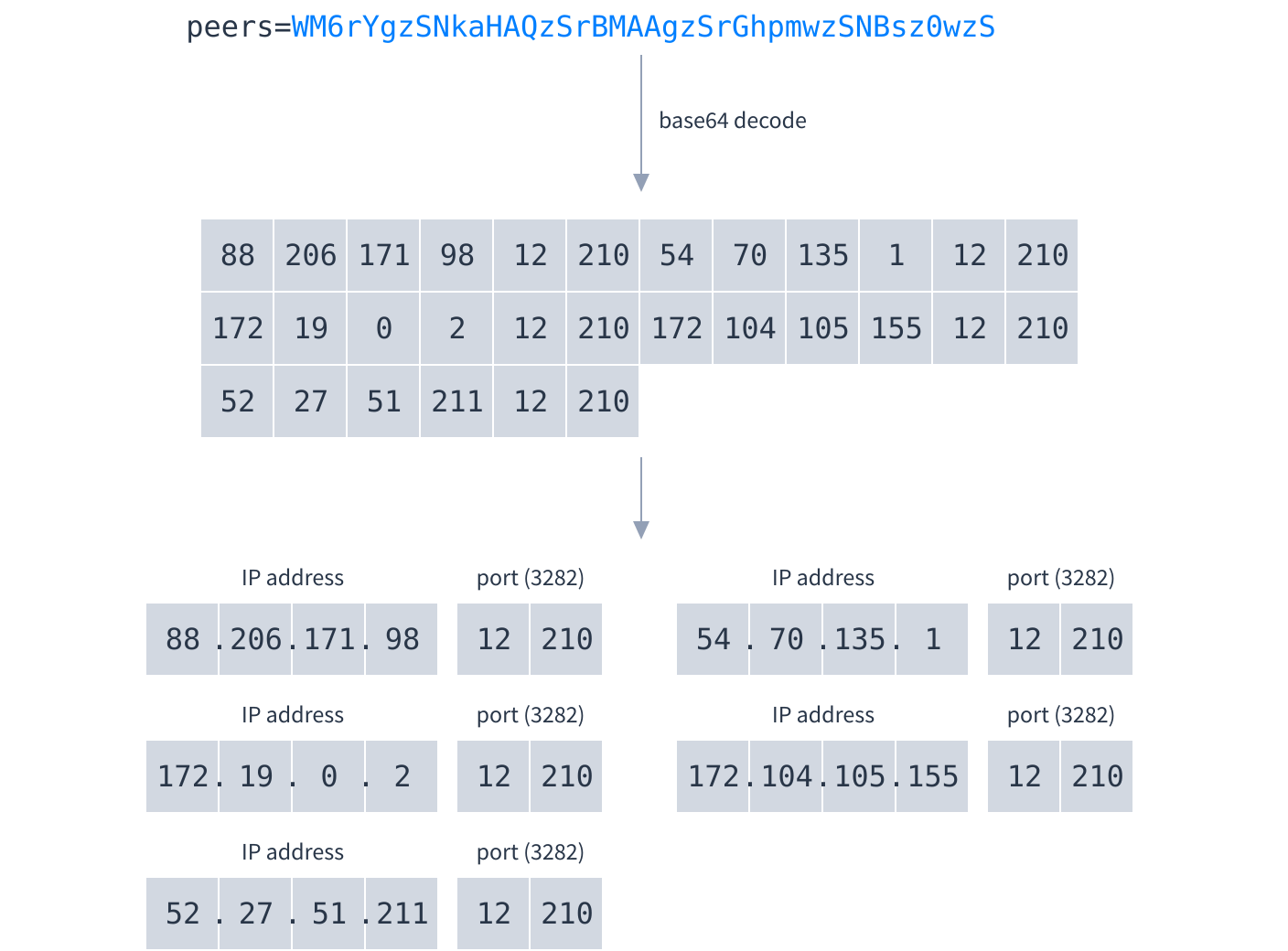
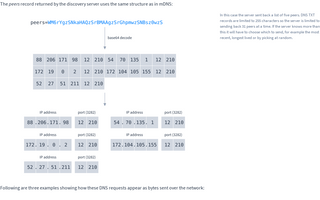
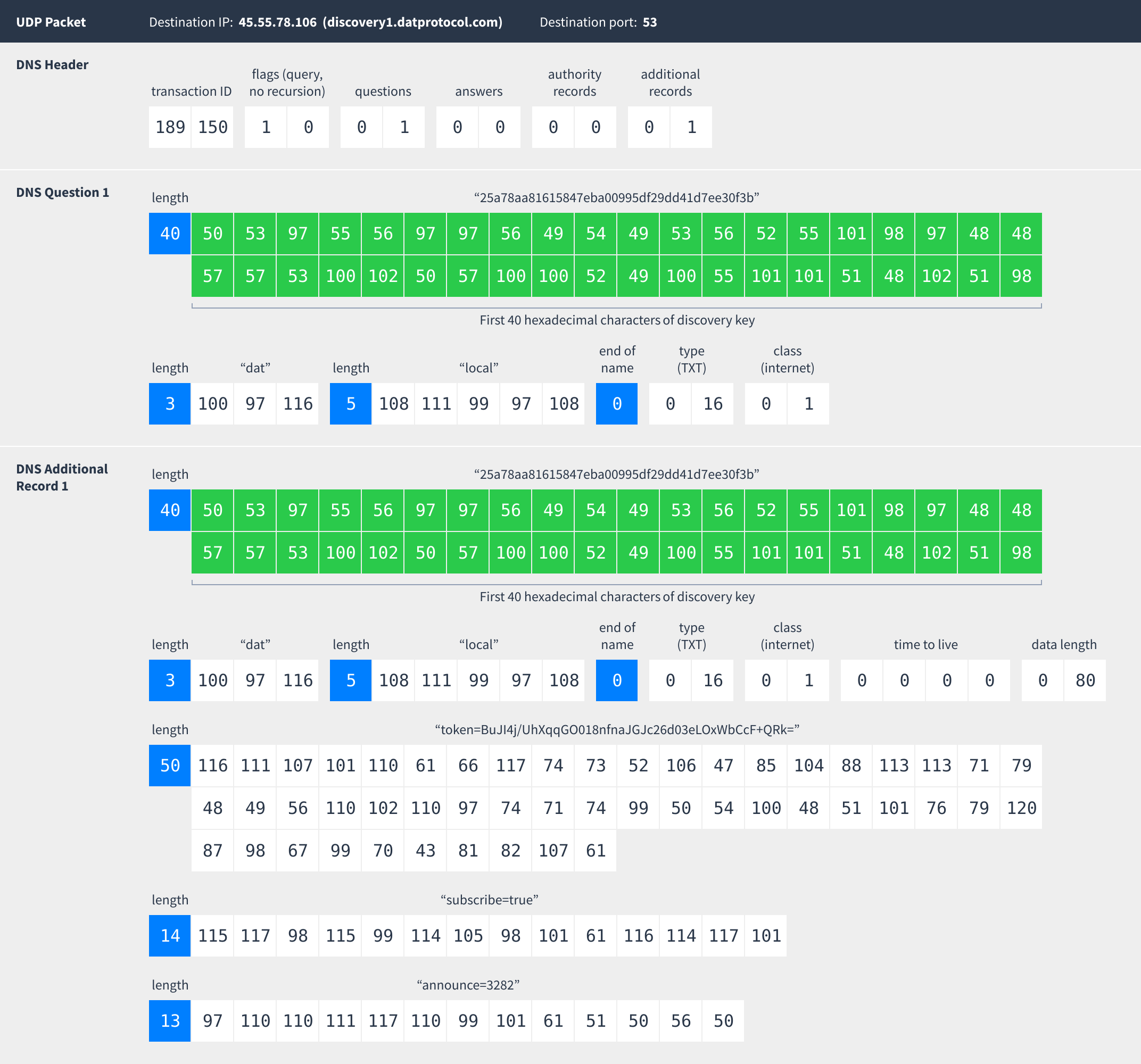
Following are three examples showing how these DNS requests appear as bytes sent over the network:
Wire protocol
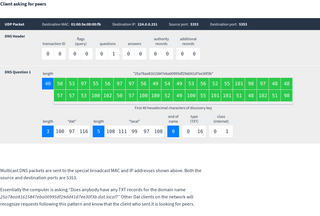
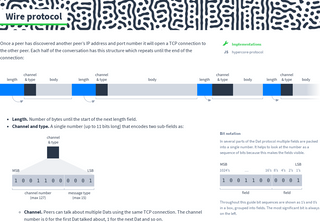
Once a peer has discovered another peer’s IP address and port number it will open a TCP connection to the other peer. Each half of the conversation has this structure which repeats until the end of the connection:

- Length. Number of bytes until the start of the next length field.
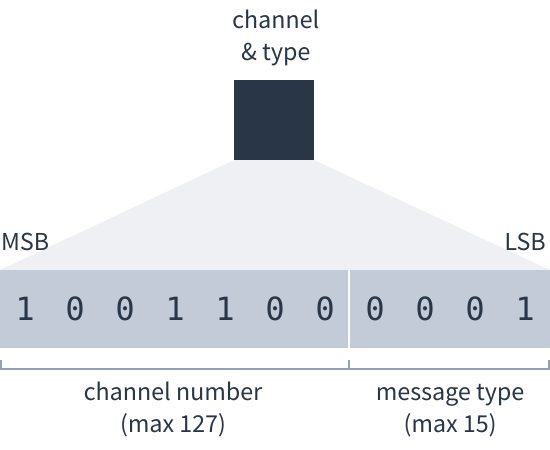
- Channel and type. A single number (up to 11 bits long) that encodes two sub-fields as:
- Channel. Peers can talk about multiple Dats using the same TCP connection. The channel number is 0 for the first Dat talked about, 1 for the next Dat and so on.
- Type. Number that says what the purpose of the message is.
- Body. Contents of the message.
| Type | Name | Meaning |
|---|---|---|
| 0 | Feed | I want to talk to you about this particular Dat |
| 1 | Handshake | I want to negotiate how we will communicate on this TCP connection |
| 2 | Info | I am either starting or stopping uploading or downloading |
| 3 | Have | I have some data that you said you wanted |
| 4 | Unhave | I no longer have some data that I previously said I had (alternatively: I didn’t store that data you just sent, please stop sending me data preemptively) |
| 5 | Want | This is what data I want |
| 6 | Unwant | I no longer want this data |
| 7 | Request | Please send me this data now |
| 8 | Cancel | Actually, don’t send me that data |
| 9 | Data | Here is the data you requested |
| 10–14 | (Unused) | |
| 15 | Extension | Some other message that is not part of the core protocol |
Varints
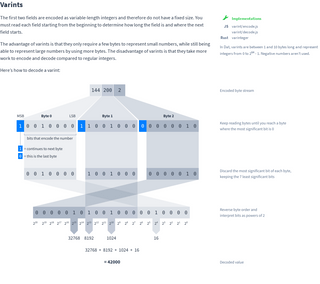
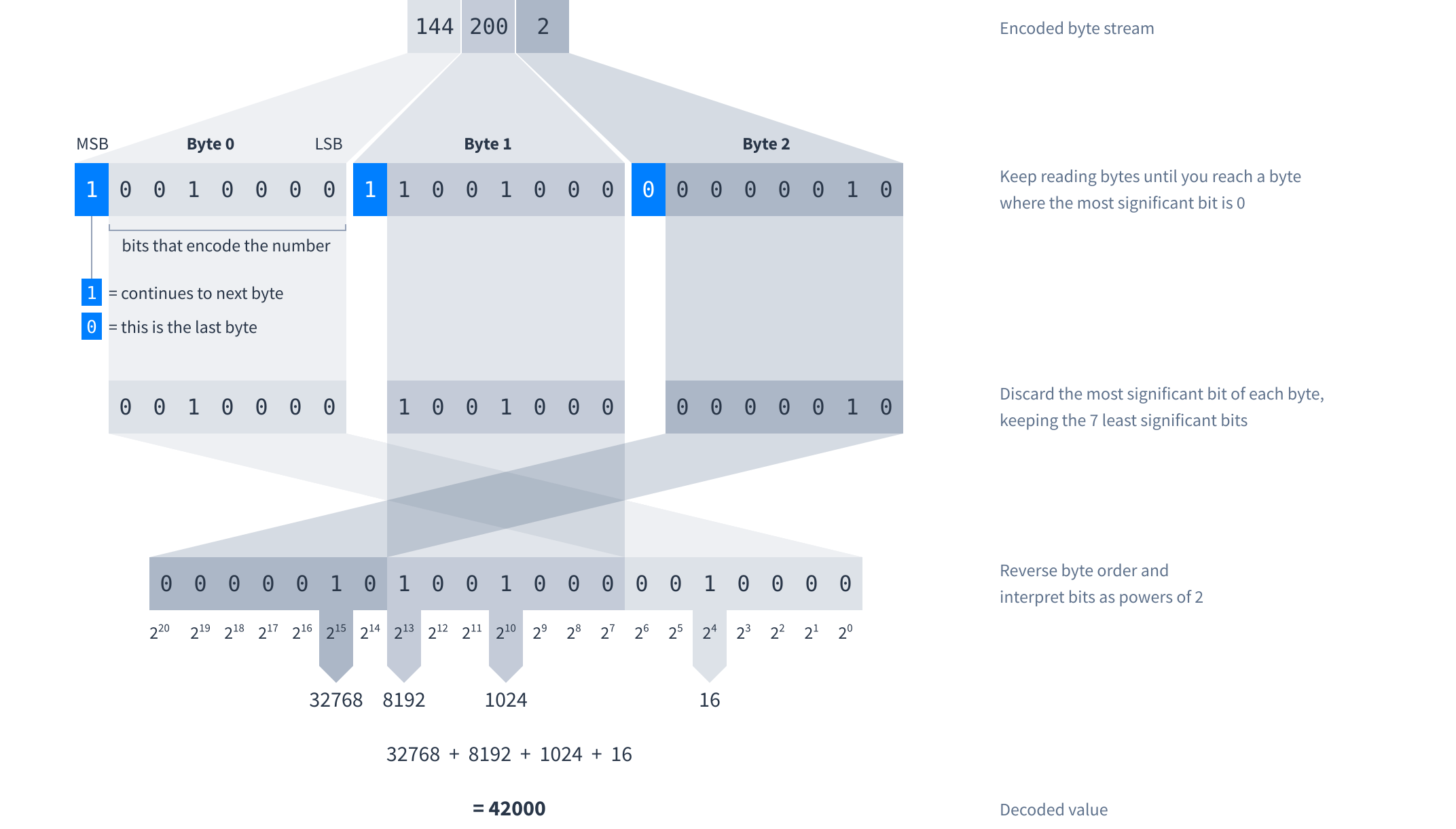
The first two fields are encoded as variable-length integers and therefore do not have a fixed size. You must read each field starting from the beginning to determine how long the field is and where the next field starts.
The advantage of varints is that they only require a few bytes to represent small numbers, while still being able to represent large numbers by using more bytes. The disadvantage of varints is that they take more work to encode and decode compared to regular integers.
Here’s how to decode a varint:
Keepalive
Keepalive messages are empty messages containing no channel number, type or body. They are discarded upon being received. Sending keepalives is necessary when there is a network middlebox that kills TCP connections which haven’t sent any data in a while. In these cases each peer periodically sends keepalive messages when no other data is being sent.
Here’s an example of several keepalive messages interleaved with messages containing actual data. Each keepalive message is a single byte of zero:

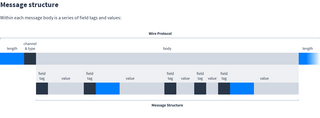
Message structure
Within each message body is a series of field tags and values:
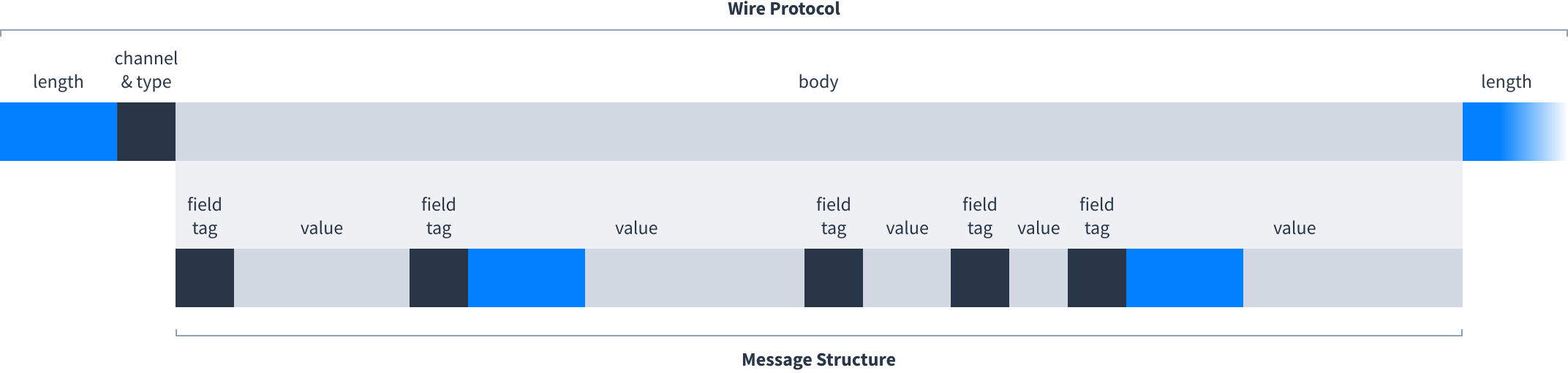
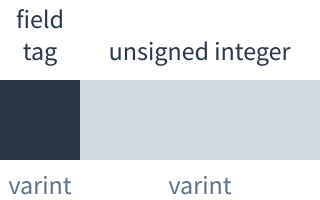
The field tag is a varint. The most significant bits indicate which field within the message this is, for example: 1 = discovery key, 2 = nonce. This is needed because messages can have missing or repeated fields. The 3 least significant bits are the type of field.
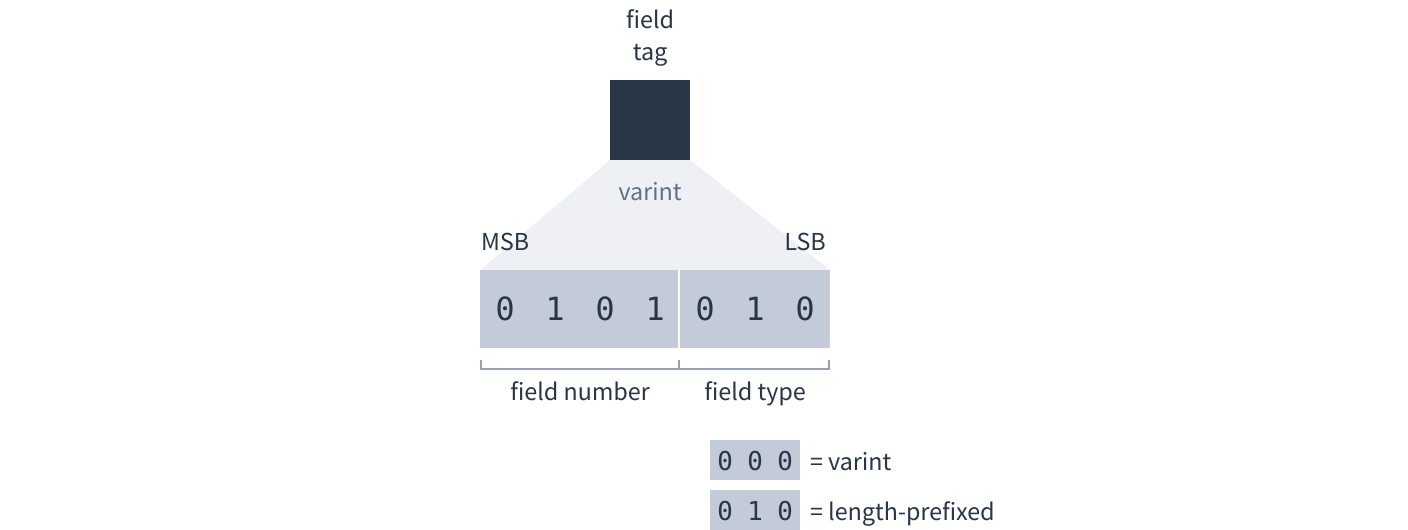
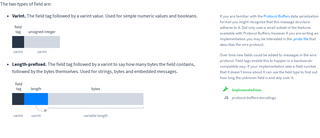
The two types of field are:
- Varint. The field tag followed by a varint value. Used for simple numeric values and booleans.
- Length-prefixed. The field tag followed by a varint to say how many bytes the field contains, followed by the bytes themselves. Used for strings, bytes and embedded messages.

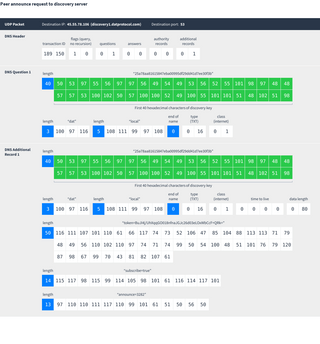
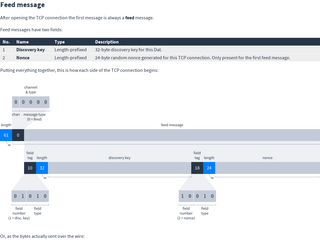
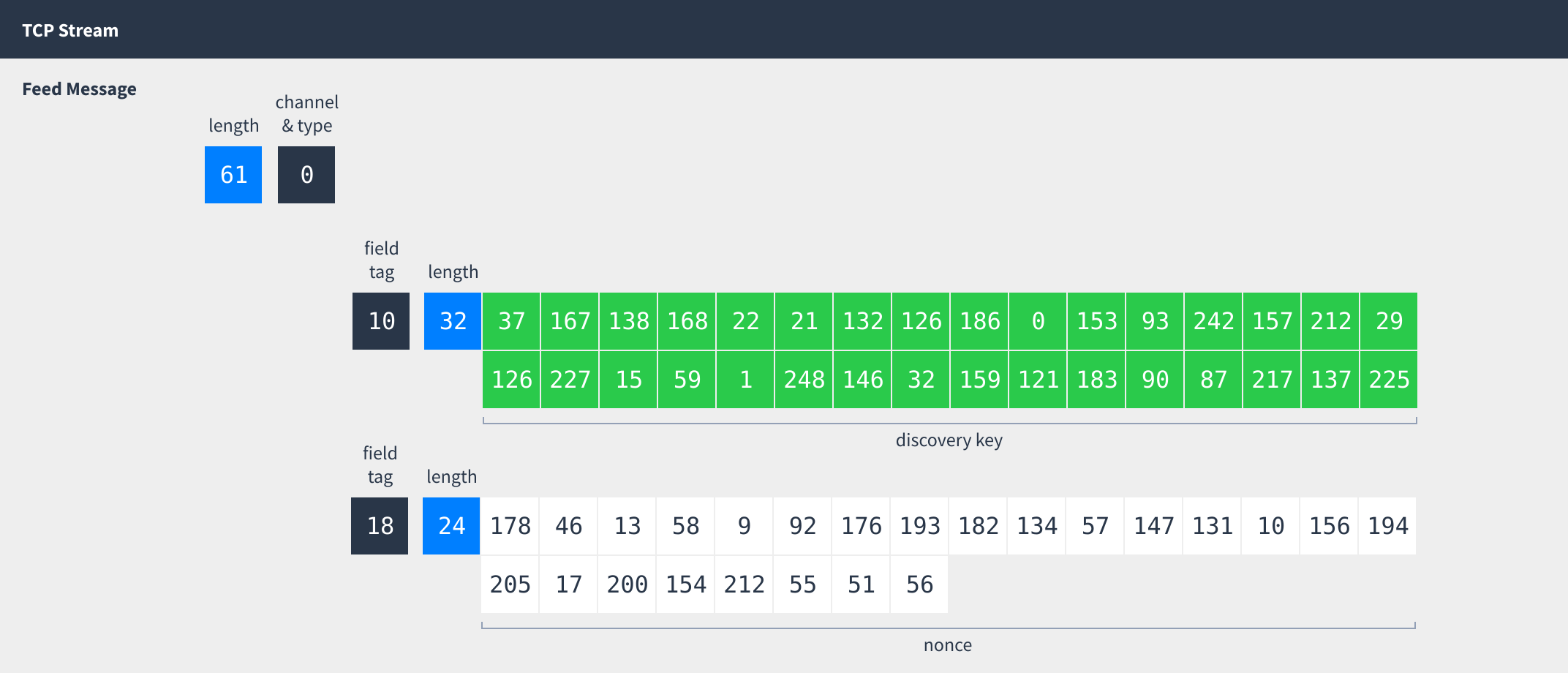
Feed message
After opening the TCP connection the first message is always a feed message.
Feed messages have two fields:
| No. | Name | Type | Description |
|---|---|---|---|
| 1 | Discovery key | Length-prefixed | 32-byte discovery key for this Dat. |
| 2 | Nonce | Length-prefixed | 24-byte random nonce generated for this TCP connection. Only present for the first feed message. |
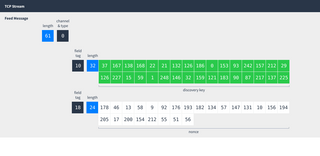
Putting everything together, this is how each side of the TCP connection begins:
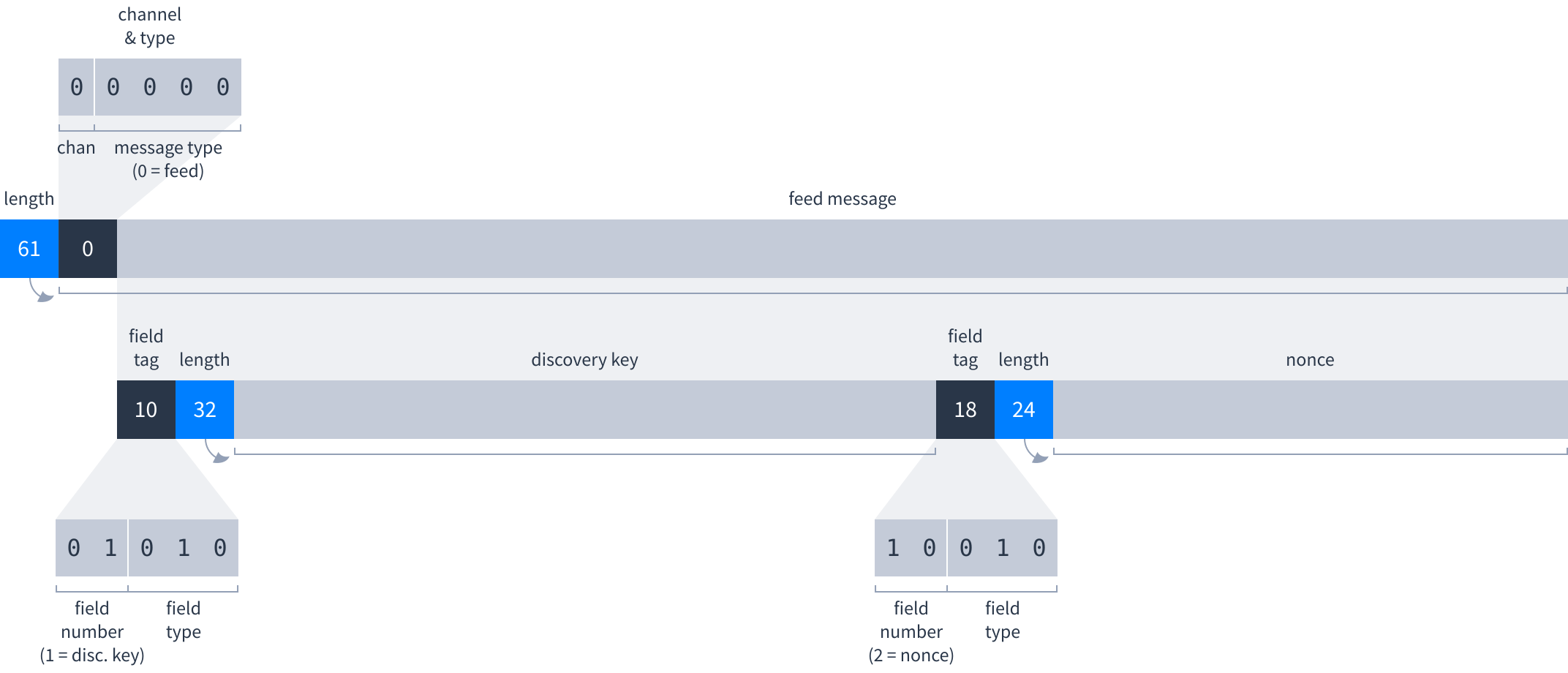
Or, as the bytes actually sent over the wire:
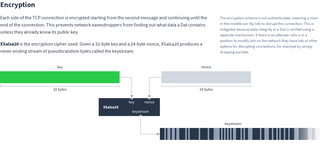
Encryption
Each side of the TCP connection is encrypted starting from the second message and continuing until the end of the connection. This prevents network eavesdroppers from finding out what data a Dat contains unless they already know its public key.
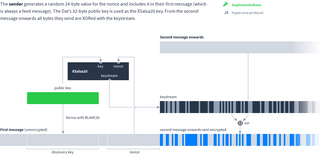
XSalsa20 is the encryption cipher used. Given a 32-byte key and a 24-byte nonce, XSalsa20 produces a never-ending stream of pseudorandom bytes called the keystream.
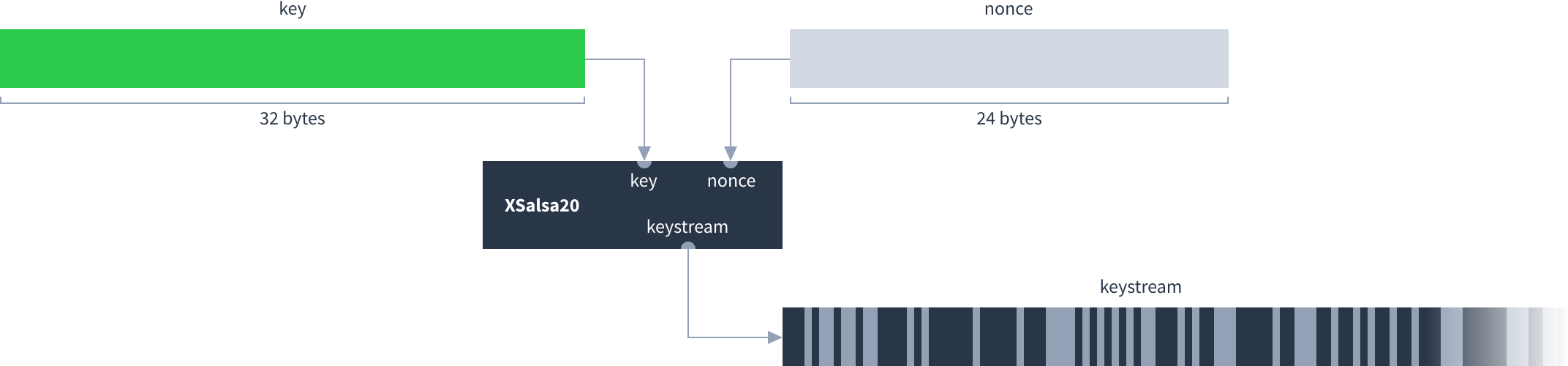
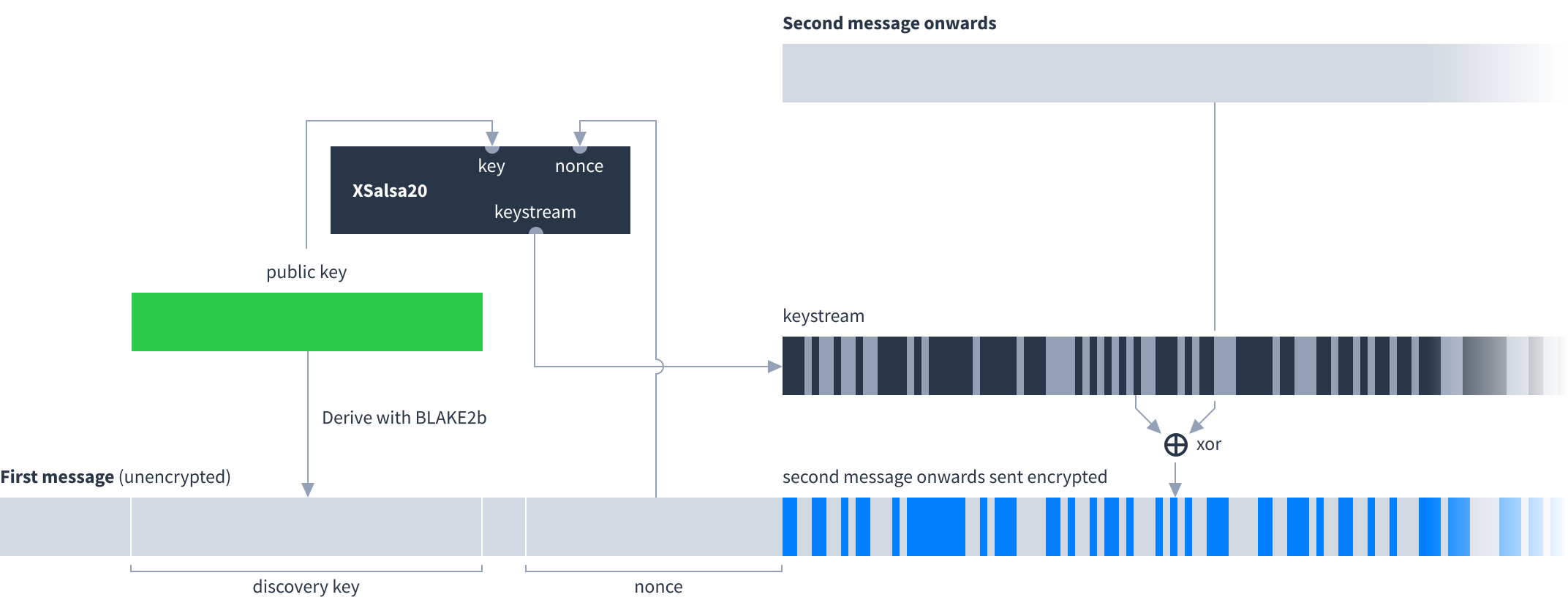
The sender generates a random 24-byte value for the nonce and includes it in their first message (which is always a feed message). The Dat’s 32-byte public key is used as the XSalsa20 key. From the second message onwards all bytes they send are XORed with the keystream.
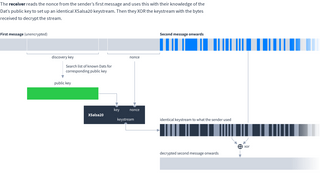
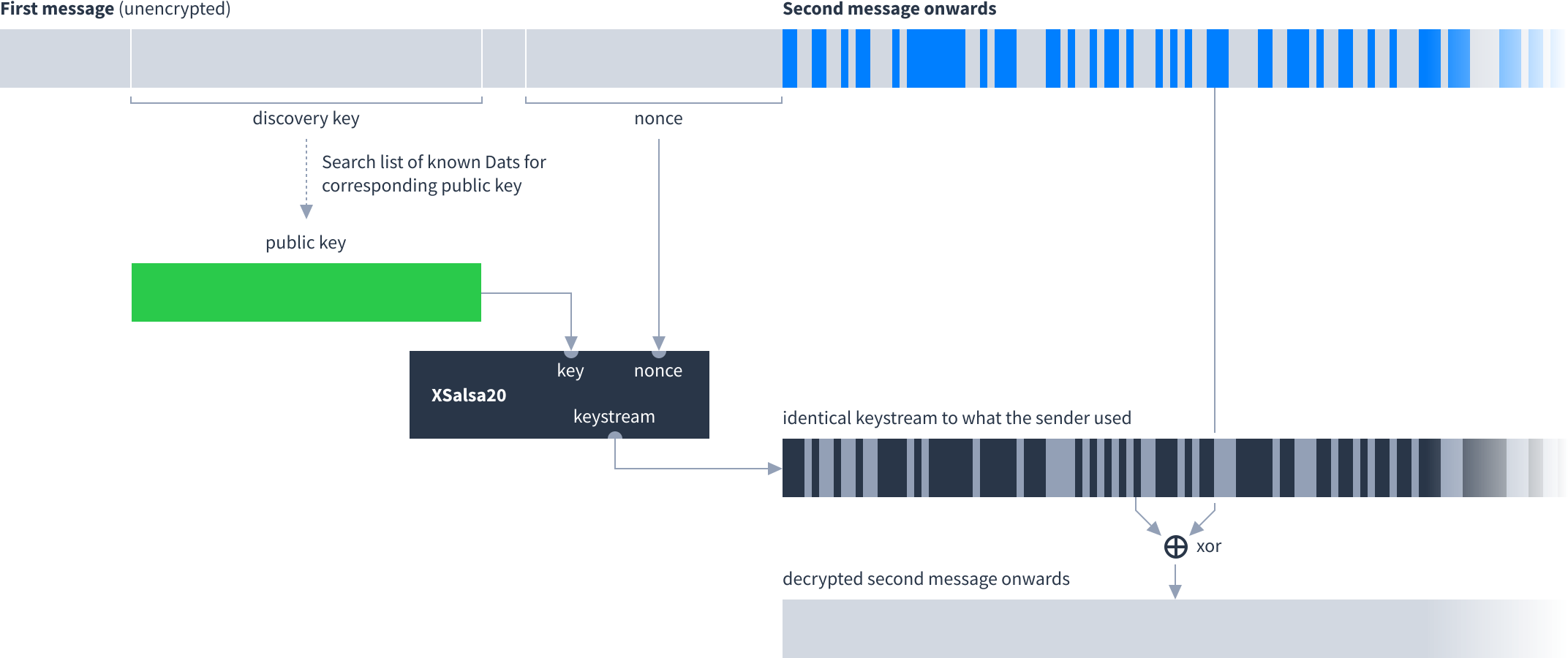
The receiver reads the nonce from the sender’s first message and uses this with their knowledge of the Dat’s public key to set up an identical XSalsa20 keystream. Then they XOR the keystream with the bytes received to decrypt the stream.
Handshake message
After the initial feed message, the second message sent on each side of the TCP connection is always a handshake message.
| No. | Name | Type | Description |
|---|---|---|---|
| 1 | ID | Length-prefixed | Random ID generated by this peer upon starting, 32 bytes long. Used to detect multiple connections to the same peer or accidental connections to itself. |
| 2 | Live | Varint | 0 = End the connection when neither peer is downloading, 1 = Keep the connection open indefinitely (only takes effect if both peers set to 1). |
| 3 | User data | Length-prefixed | Arbitrary bytes that can be used by higher-level applications for any purpose. Remember that any data put in here is not protected from tampering as it passes through the network. Additionally, any eavesdropper who knows the Dat’s public key can read this. |
| 4 | Extensions | Length-prefixed | Names of any extensions the peer wants to use, for example: “session-data”. This field can appear multiple times, one for each extension. Both peers need to request an extension in their handshake messages for it to become active. |
| 5 | Acknowledge | Varint | 0 = No need to acknowledge each chunk of data received, 1 = Must acknowledge each chunk of data received. |
Data model
After completing the handshake peers begin requesting data from each other. Dats contain a list of variable-sized chunks of bytes. New chunks can be added to the end by the Dat’s author, but existing chunks can’t be deleted or modified.

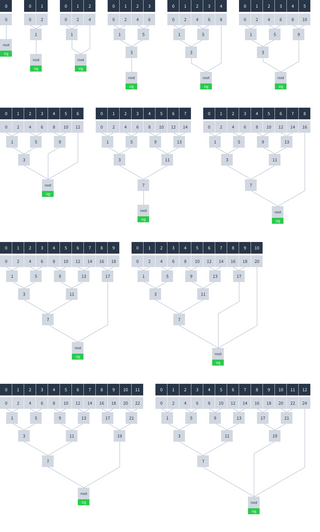
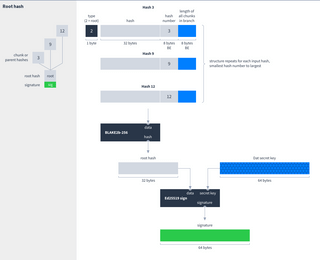
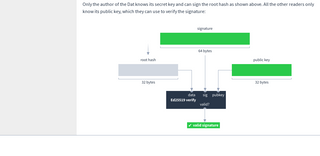
Hashes are used to verify the integrity of data within a Dat. Each chunk of data has a corresponding hash. There are also parent hashes which verify the integrity of two other hashes. Parent hashes form a tree structure. In this example the integrity of all the data can be verified if you know hash number 3:
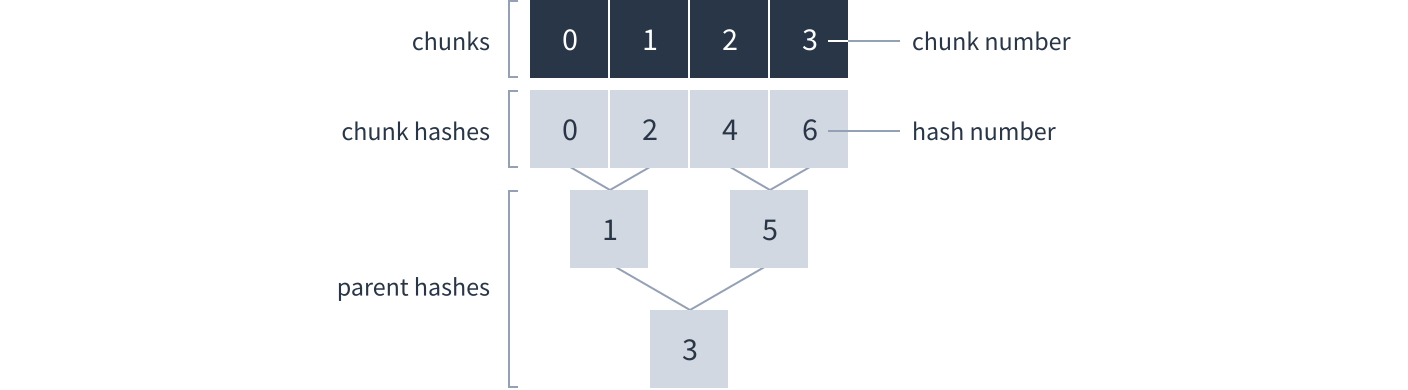
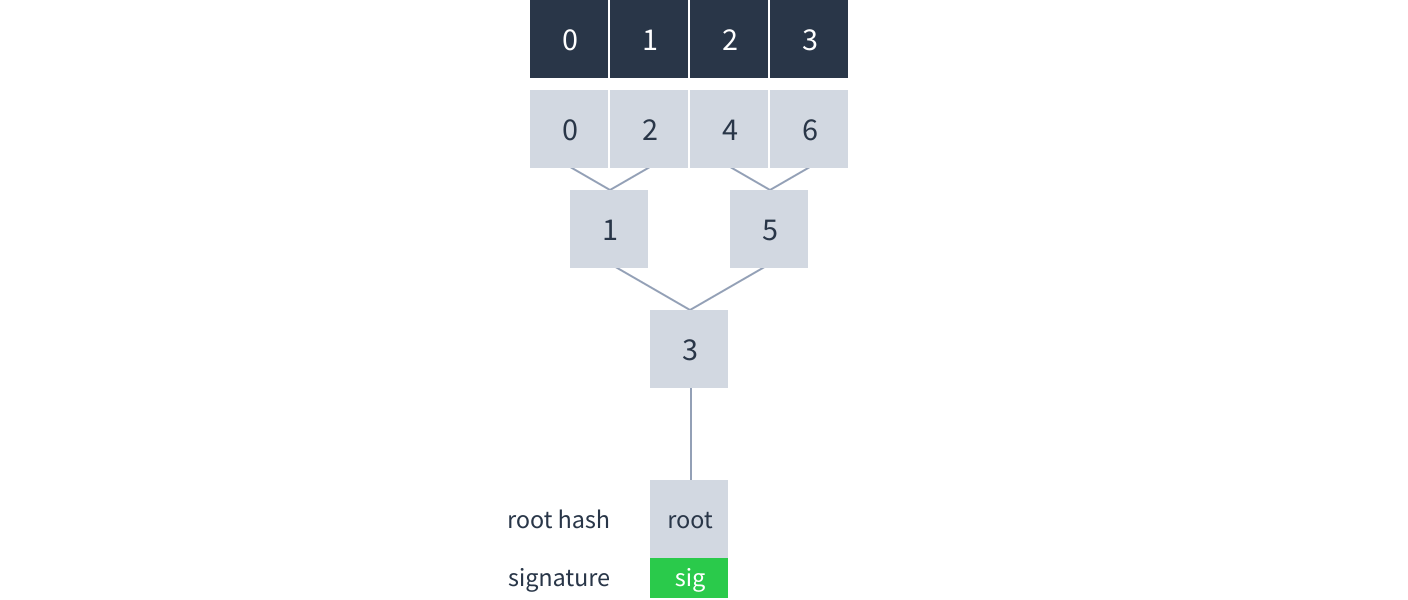
Each time the author adds new chunks they calculate a root hash and sign it with the Dat’s secret key. Downloaders can use the Dat’s public key to verify the signature, which in turn verifies the integrity of all the other hashes and chunks.
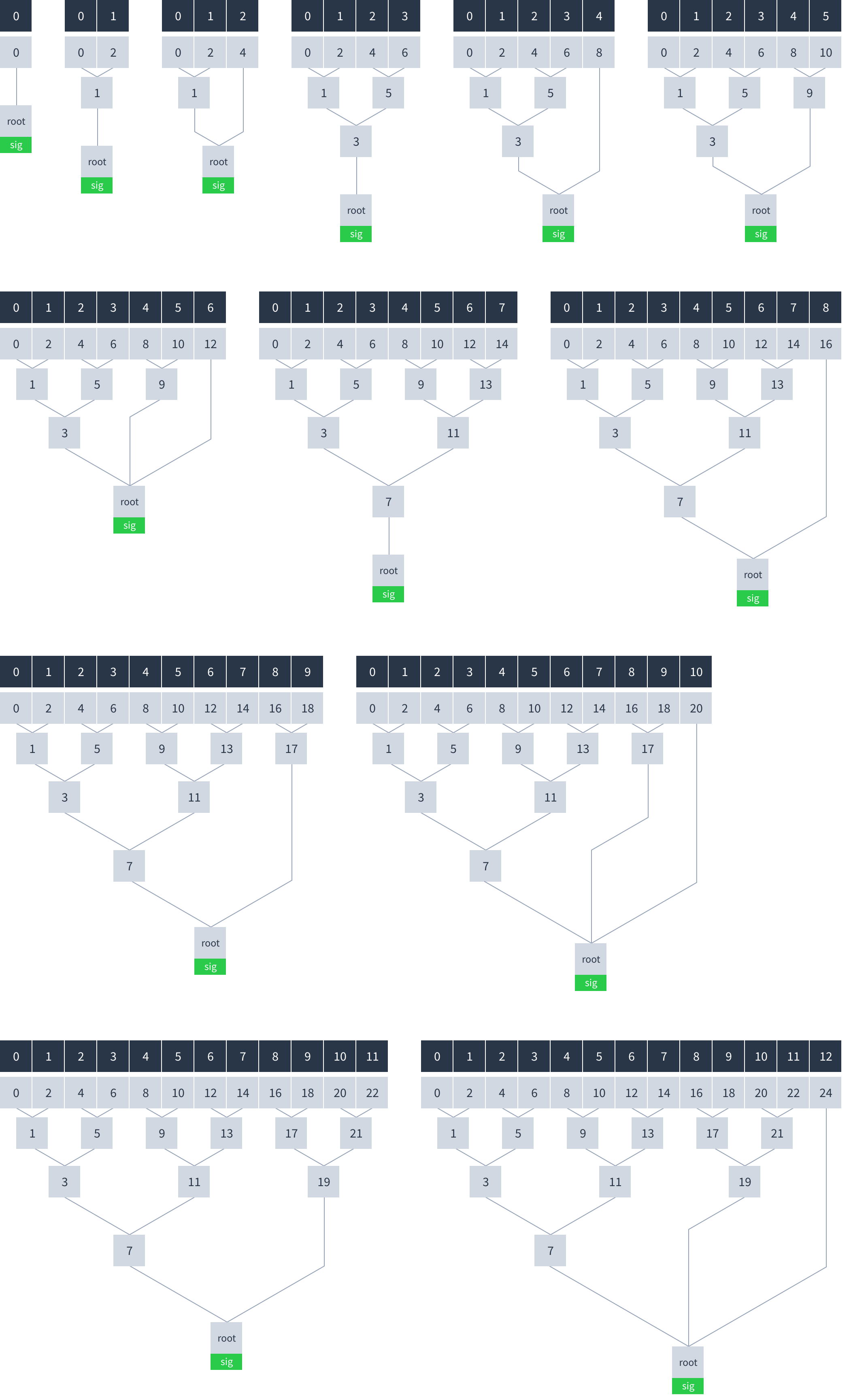
Depending on the number of chunks, the root hash can have more than one input. The root hash combines as many parent or chunk hashes as necessary to cover all the chunks. Here is how the hash tree looks with different numbers of chunks:
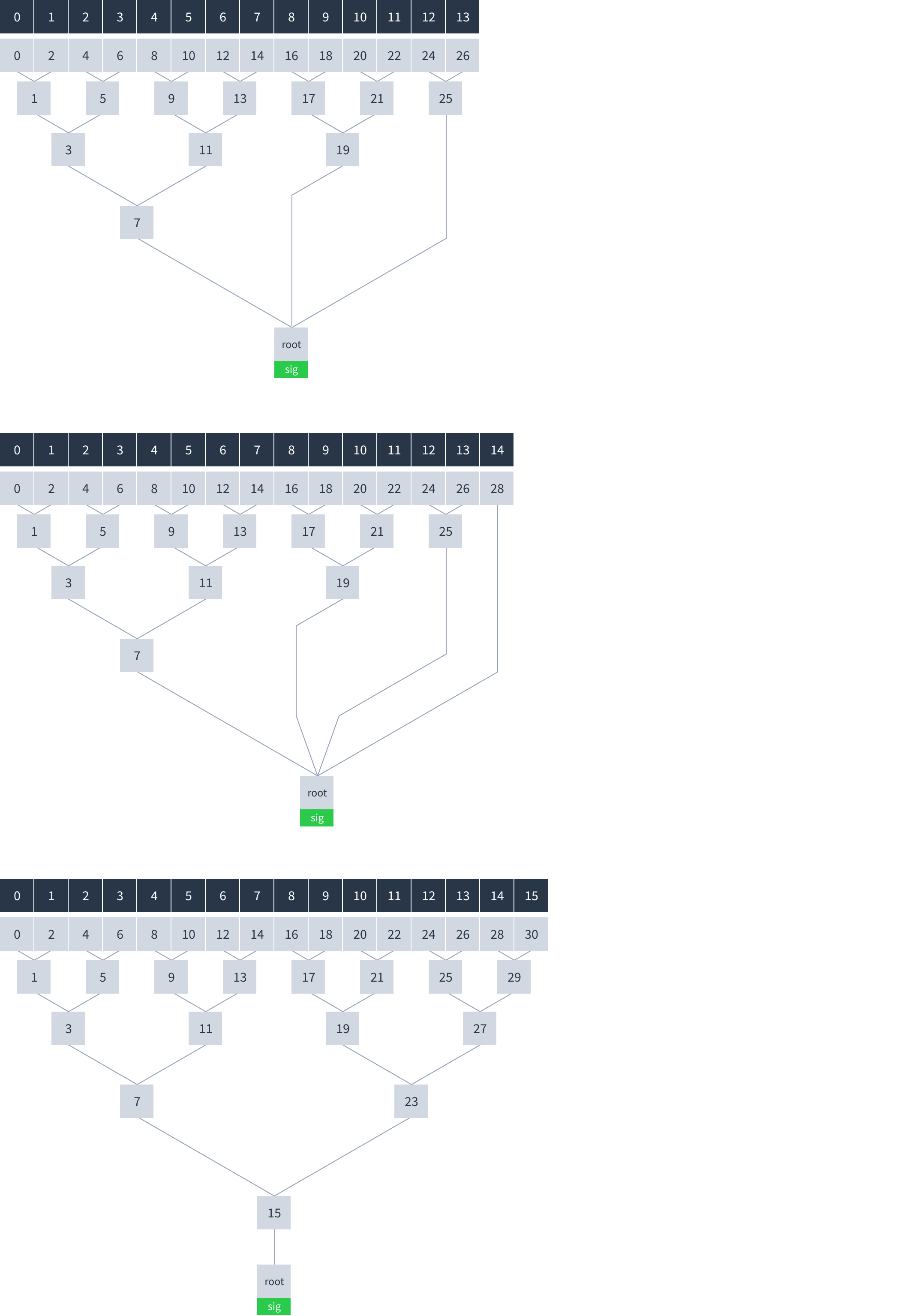
Hashes and signatures
The three types of hash seen in the hash tree are:
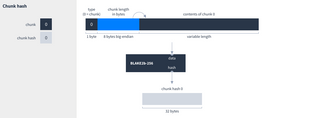
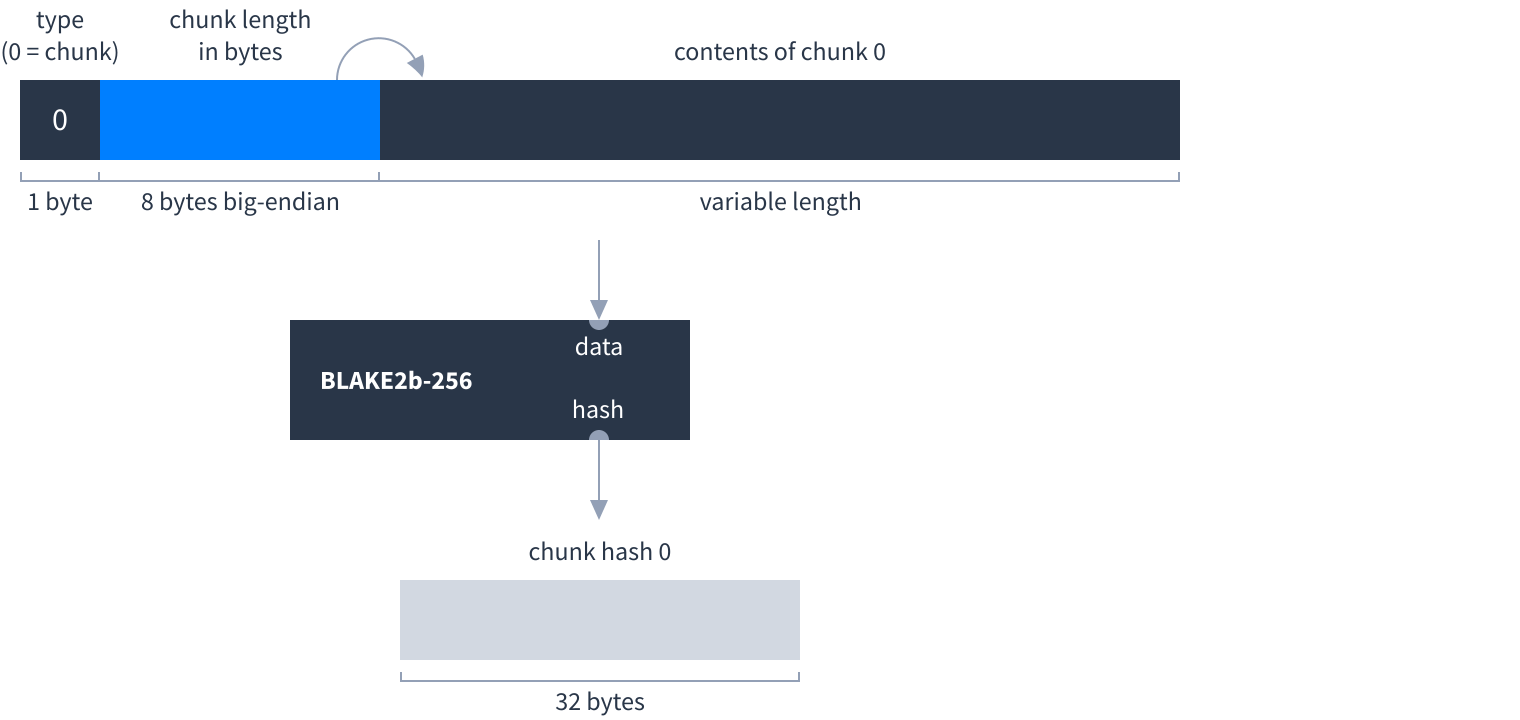
- Chunk hashes, which hash the contents of a single chunk.
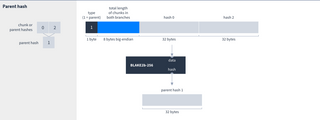
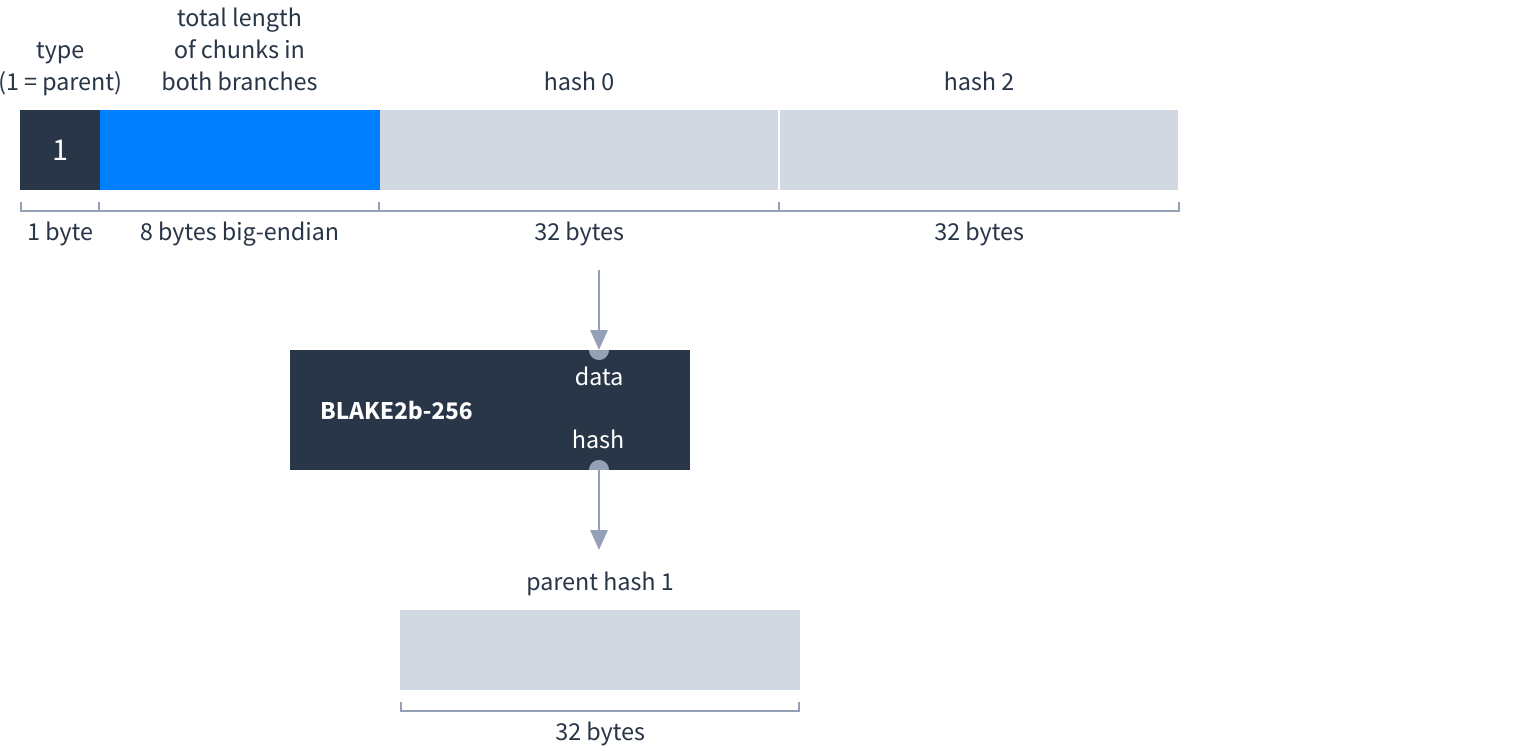
- Parent hashes, which hash two other hashes forming a tree structure.
- Root hashes, which sit at the root of the tree and are signed by the Dat’s author.
Each type of hash has a specific way to construct it:
| Type of hash | Steps to construct |
|---|---|
Chunk hash
|
 |
Parent hash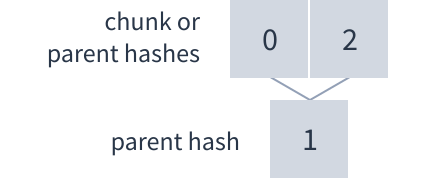
|
 |
Root hash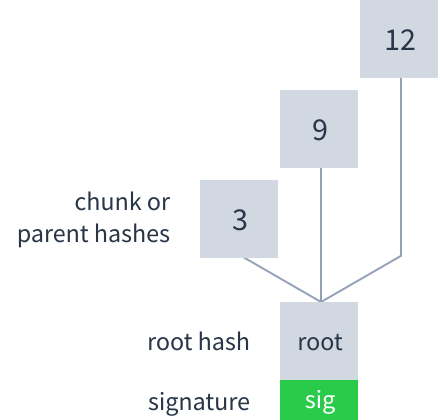
|
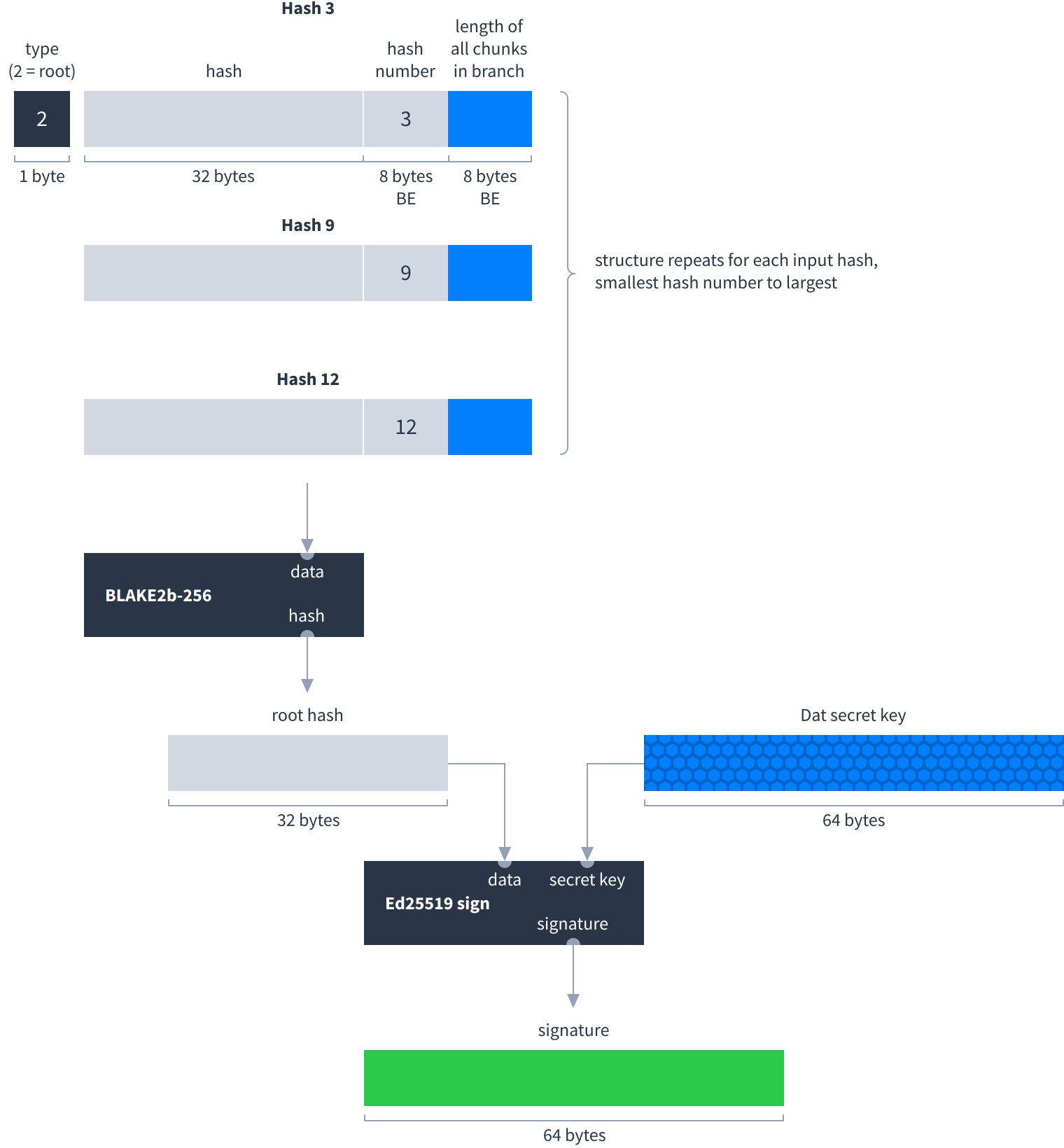
Only the author of the Dat knows its secret key and can sign the root hash as shown above. All the other readers only know its public key, which they can use to verify the signature: 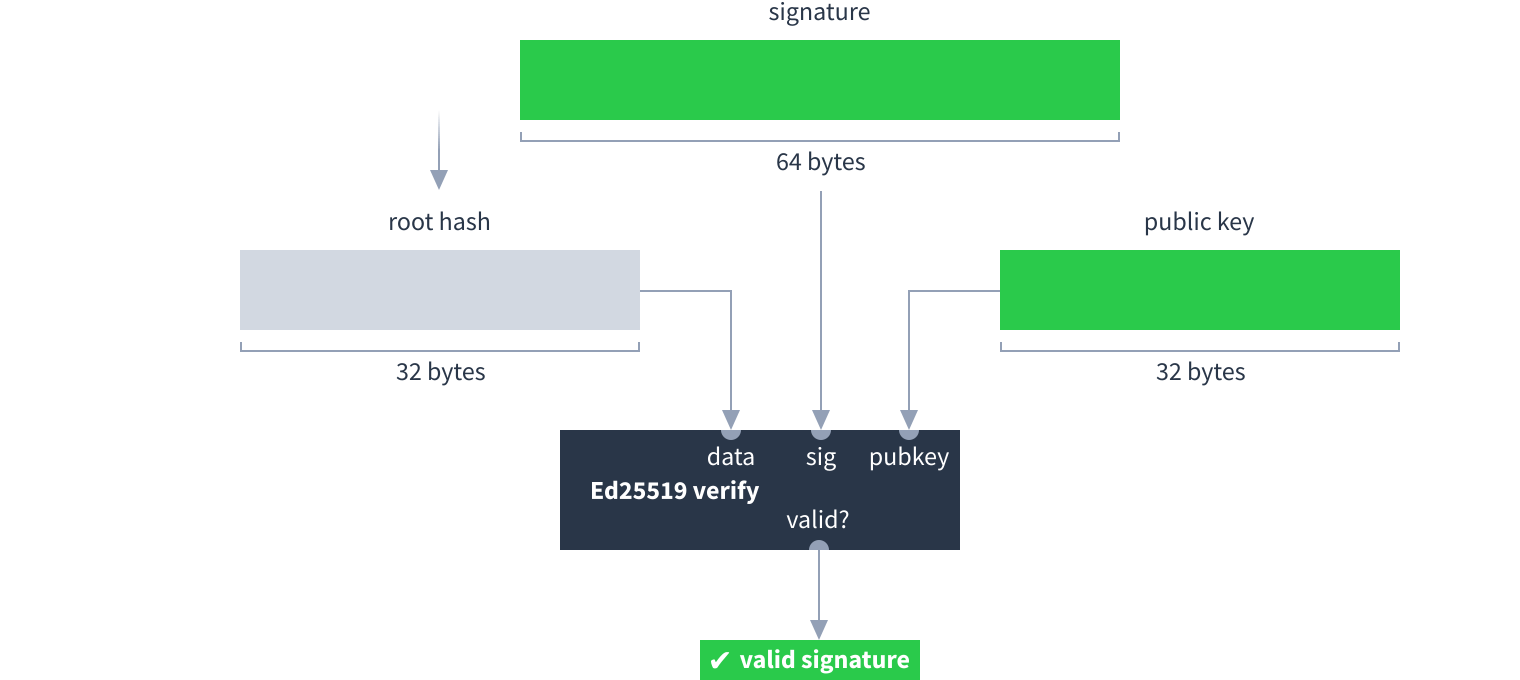
|
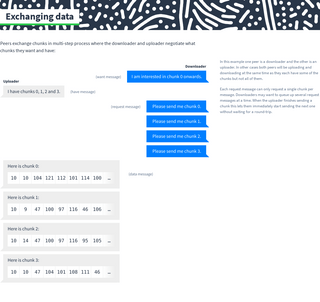
Exchanging data
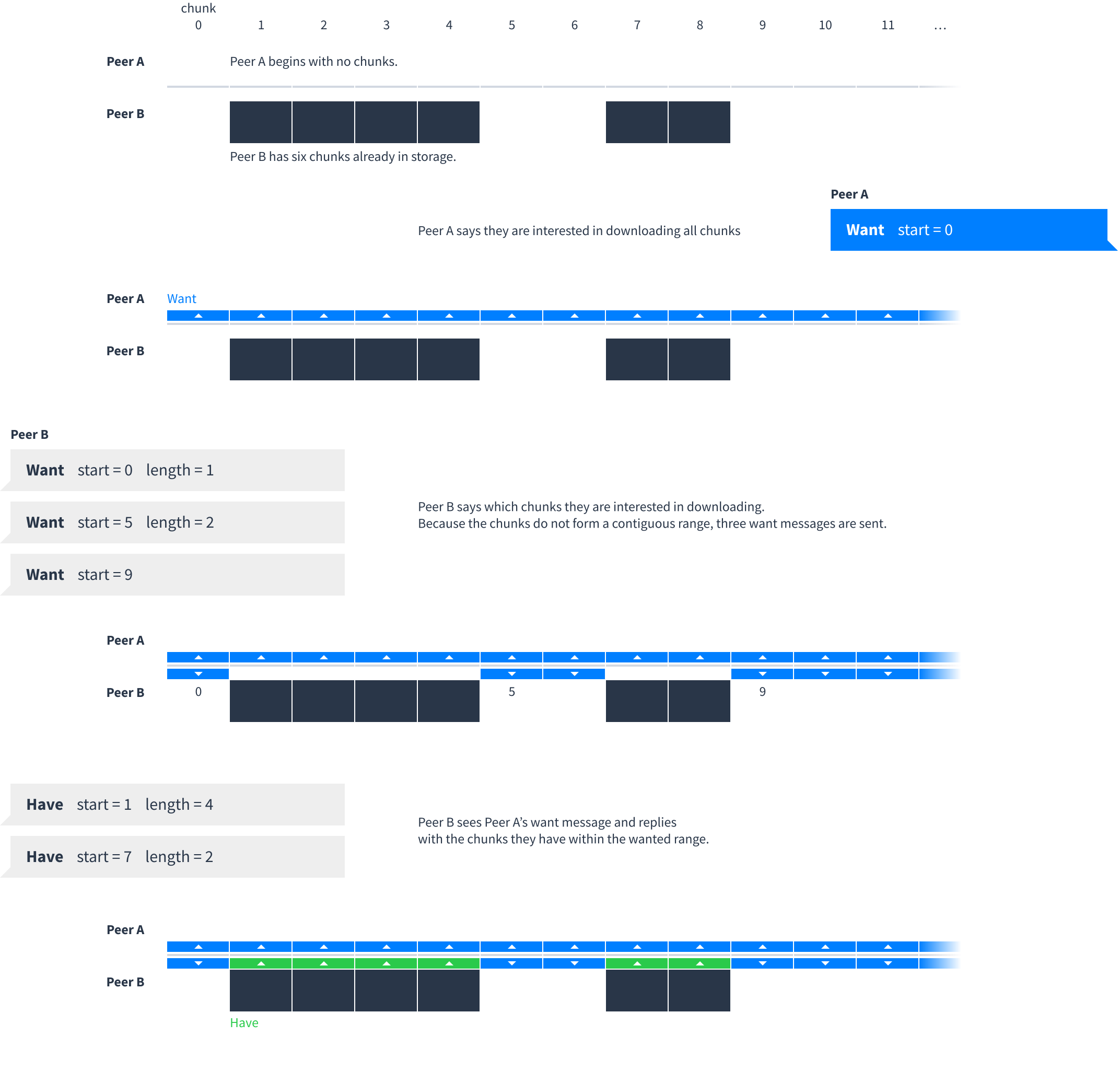
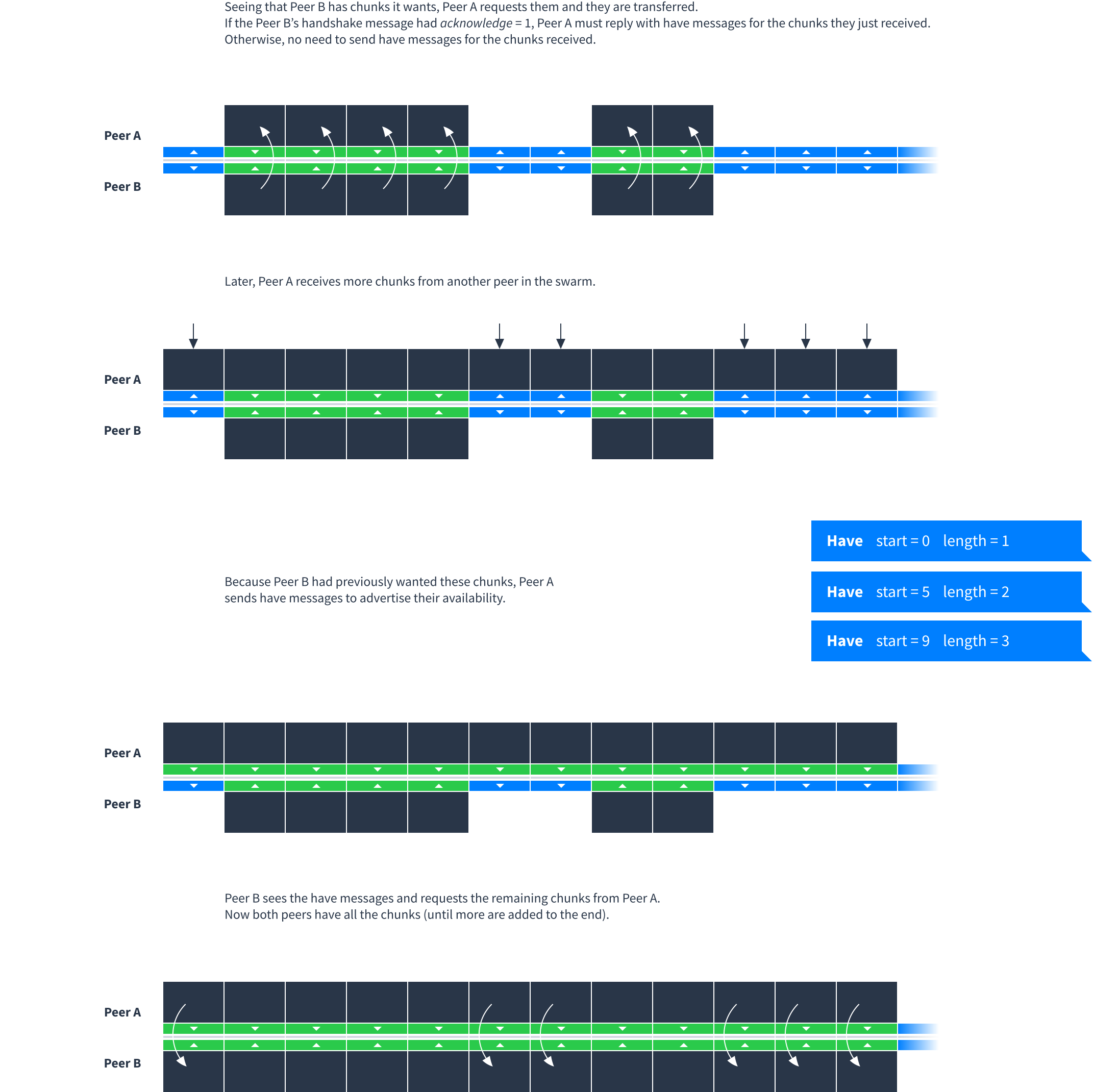
Peers exchange chunks in multi-step process where the downloader and uploader negotiate what chunks they want and have:
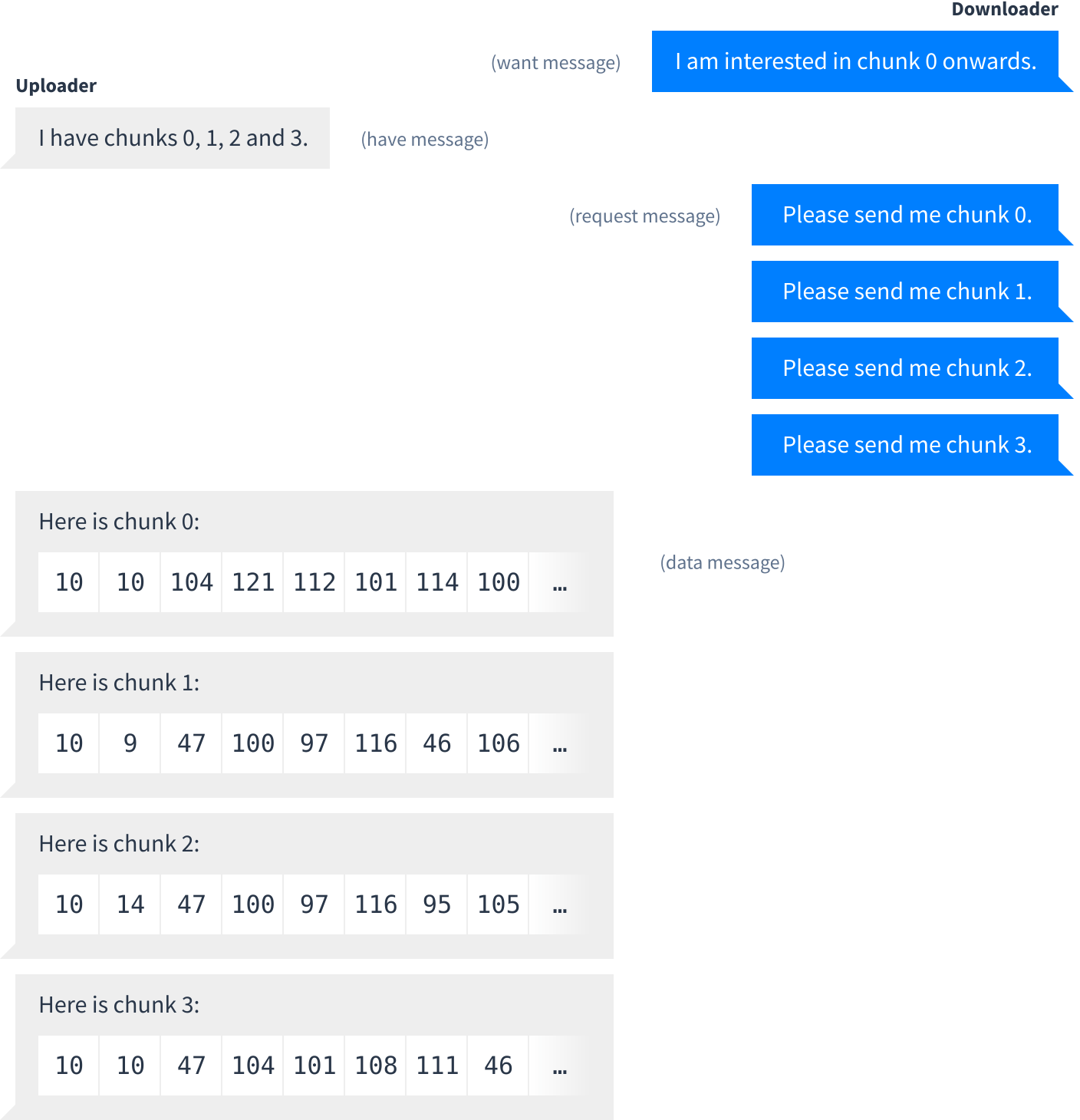
Want and have
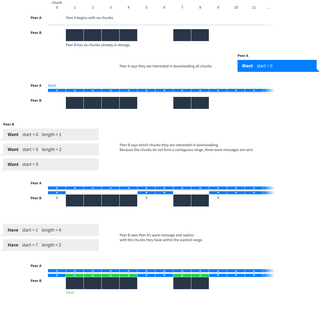
Each peer remembers which chunks the other peer wants and has.
- Wanting a chunk means “I want to download this chunk, please tell me if you have it”.
- Having a chunk means “I know you want this chunk and I will send it if you ask for it”. If a peer tells you they are only interested in a small range of chunks then you only have to tell them about chunks within that range.
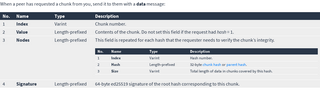
As peers download (or even delete) data, the list of chunks they want and have will change. This state is communicated with four message types: want, unwant, have and unhave. Each of these four messages has the same structure which indicates a contiguous range of chunks:
| No. | Name | Type | Description |
|---|---|---|---|
| 1 | Start | Varint | Number of the first chunk you want/unwant/have/unhave. Chunk numbering starts at 0. |
| 2 | Length | Varint | 1 = Just the start chunk, 2 = The start chunk and the next one, and so on. Omit this field to select all following chunks to the end of the Dat, including new chunks as they are added. |
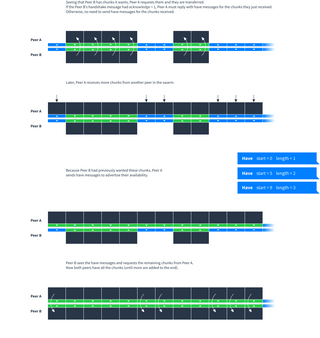
Here is an example showing typical use of have and want messages between two peers:
Have bitfield
If you have lots of little, non-contiguous ranges of data it can take a lot of have messages to tell your peer exactly what you have. There is an alternate form of the have message for this purpose. It is efficient at representing both contiguous and non-contiguous ranges of data.
This form of the have message only has one field:
| No. | Name | Type | Description |
|---|---|---|---|
| 3 | Bitfield | Length-prefixed | A sequence of contiguous and non-contiguous chunk ranges. |
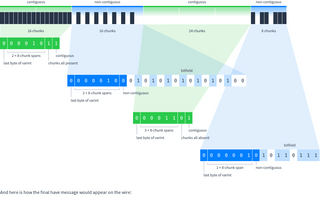
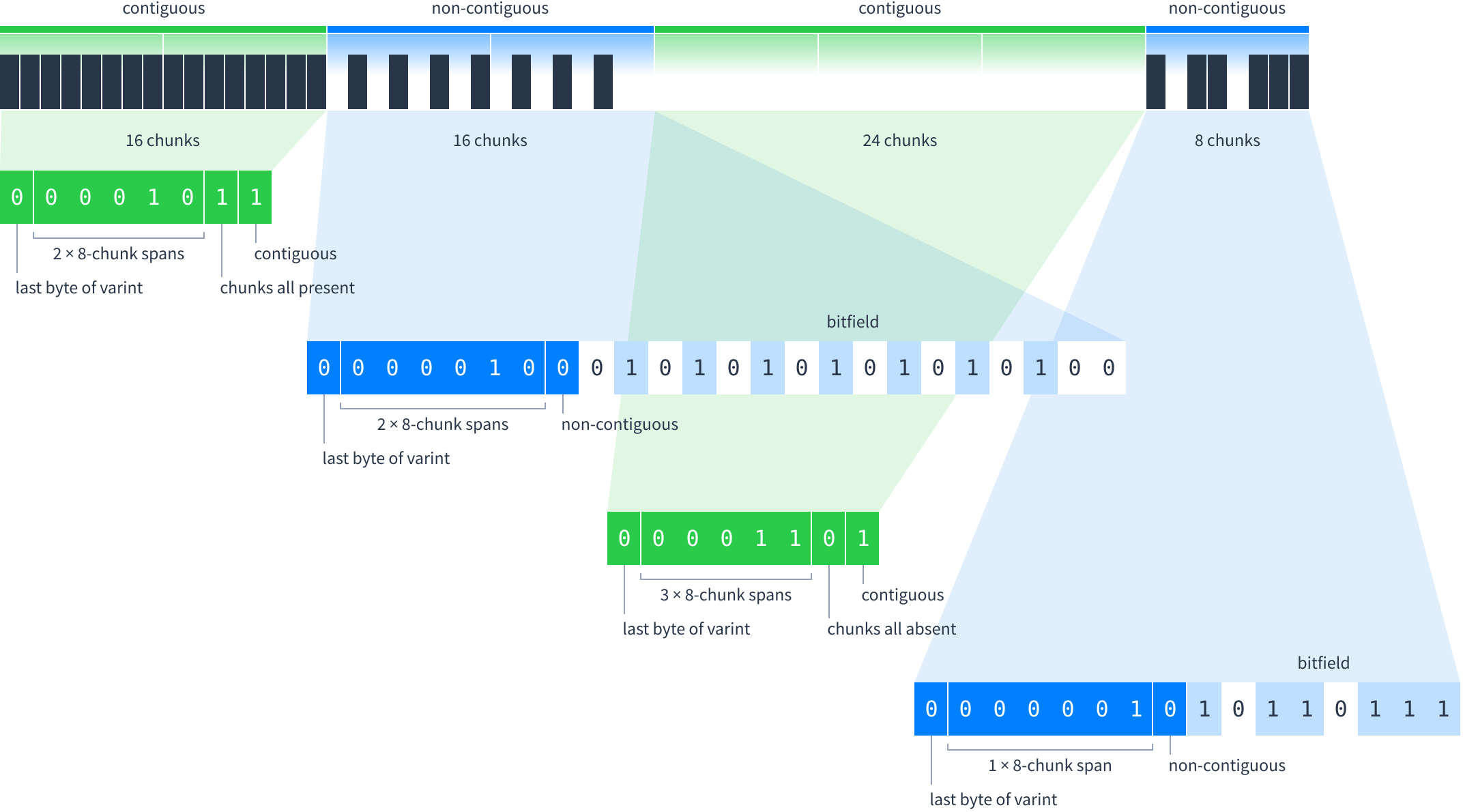
For example, let’s look at the chunks this peer has. Normally this would take 11 messages to represent:

Instead, divide the chunks into ranges where each range is either contiguous (all chunks present or none present), or non-contiguous (some chunks present). The ranges must be multiples of 8 chunks long.

Ranges are encoded as:
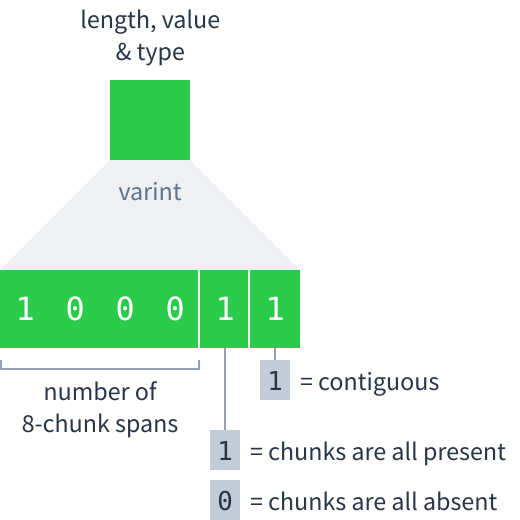
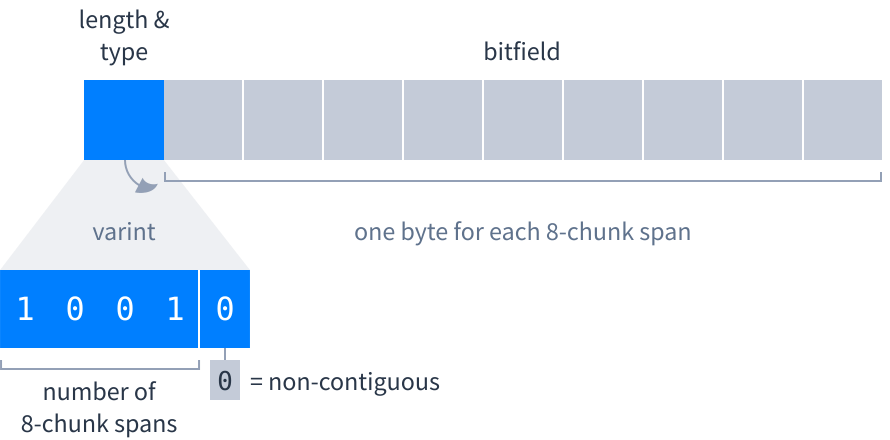
- Contiguous. A single varint that contains sub-fields saying how many 8-chunk spans there are and whether all the chunks are present or absent.
- Non-contiguous. A varint saying how many 8-chunk spans the following bitfield represents (which is also its length in bytes), followed by the bitfield.
Putting everything together, here are the bits used to encode the chunks this peer has:
And here is how the final have message would appear on the wire:

Requesting data
Once your peer has told you that they have a chunk you want, send a request message to ask them for it:
| No. | Name | Type | Description |
|---|---|---|---|
| 1 | Index | Varint | Number of the chunk to send back. This field must be present even when using the bytes field below. |
| 2 | Bytes | Varint | If this field is present, ignore the index field and send back the chunk containing this byte. Useful if you don’t know how big each chunk is but you want to seek to a specific byte. |
| 3 | Hash | Varint | 0 = Send back the data in this chunk as well as hashes needed to verify it, 1 = Don’t send back the data in this chunk, only send the hashes. |
| 4 | Nodes | Varint | Used to request additional hashes needed to verify the integrity of this chunk. 0 = Send back all hashes needed to verify this chunk, 1 = Just send the data, no hashes. For other values that can be used to request specific hashes from the hash tree, see the Wire Protocol specification. |
If you no longer want a chunk you requested, send a cancel message:
| No. | Name | Type | Description |
|---|---|---|---|
| 1 | Index | Varint | Number of the chunk to cancel. This field must be present even when using the bytes field below. |
| 2 | Bytes | Varint | If this field is present, ignore the index field and cancel the request for the chunk containing this byte. |
| 3 | Hash | Varint | Set to the same value as the hash field of the request you want to cancel. |
Cancel messages can be used if you preemptively requested a chunk from multiple peers at the same time. Upon receiving the chunk from the fastest peer, send cancel messages to the others.
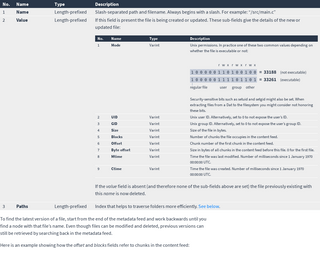
When a peer has requested a chunk from you, send it to them with a data message:
| No. | Name | Type | Description | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Index | Varint | Chunk number. | ||||||||||||||||
| 2 | Value | Length-prefixed | Contents of the chunk. Do not set this field if the request had hash = 1. | ||||||||||||||||
| 3 | Nodes | Length-prefixed |
This field is repeated for each hash that the requester needs to verify the chunk’s integrity.
|
||||||||||||||||
| 4 | Signature | Length-prefixed | 64-byte ed25519 signature of the root hash corresponding to this chunk. |
Files and folders
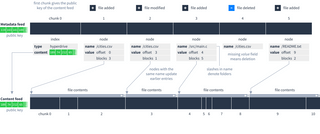
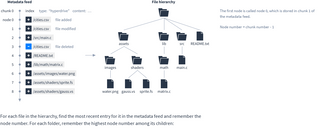
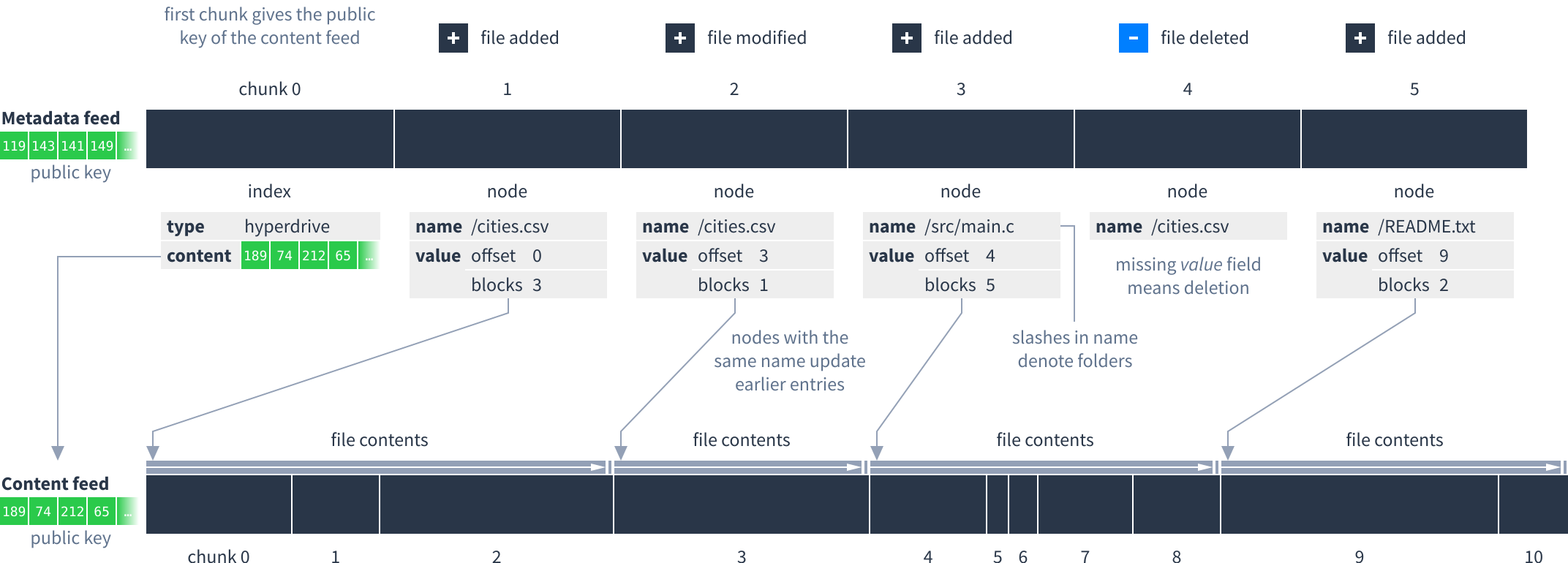
Dat uses two coupled feeds to represent files and folders. The metadata feed contains the names, sizes and other metadata for each file, and its typically quite small even when the Dat contains a lot of data. The content feed contains the actual file contents. The metadata feed points to where in the content feed each file is located, so you only need to fetch the contents of files you are interested in.

The first chunk of the metadata feed is always an index chunk. Check that the type field contains the word “hyperdrive”. If so, the content field is the public key of the content feed.
| No. | Name | Type | Description |
|---|---|---|---|
| 1 | Type | Length-prefixed | What sort of data is contained in this Dat. For Dats using the concept of files and folders this is “hyperdrive”. |
| 2 | Content | Length-prefixed | 32-byte public key of the content feed. |
After the index all following chunks in the metadata feed are nodes, which store file metadata. Nodes have these fields:
| No. | Name | Type | Description | ||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Name | Length-prefixed | Slash-separated path and filename. Always begins with a slash. For example: “/src/main.c” | ||||||||||||||||||||||||||||||||||||||||
| 2 | Value | Length-prefixed |
If this field is present the file is being created or updated. These sub-fields give the details of the new or updated file:
If the value field is absent (and therefore none of the sub-fields above are set) the file previously existing with this name is now deleted. |
||||||||||||||||||||||||||||||||||||||||
| 3 | Paths | Length-prefixed | Index that helps to traverse folders more efficiently. See below. |
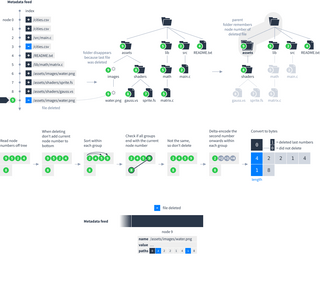
To find the latest version of a file, start from the end of the metadata feed and work backwards until you find a node with that file’s name. Even though files can be modified and deleted, previous versions can still be retrieved by searching back in the metadata feed.
Here is an example showing how the offset and blocks fields refer to chunks in the content feed:
Paths index
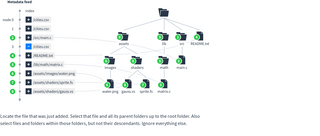
Scanning through the list of all files added, modified or deleted would be slow for Dats that contain lots of files or a long history. To make this faster, every node in the metadata feed contains extra information in the paths field to help traverse folders.

To calculate a paths field, start by constructing a file hierarchy from the metadata feed:
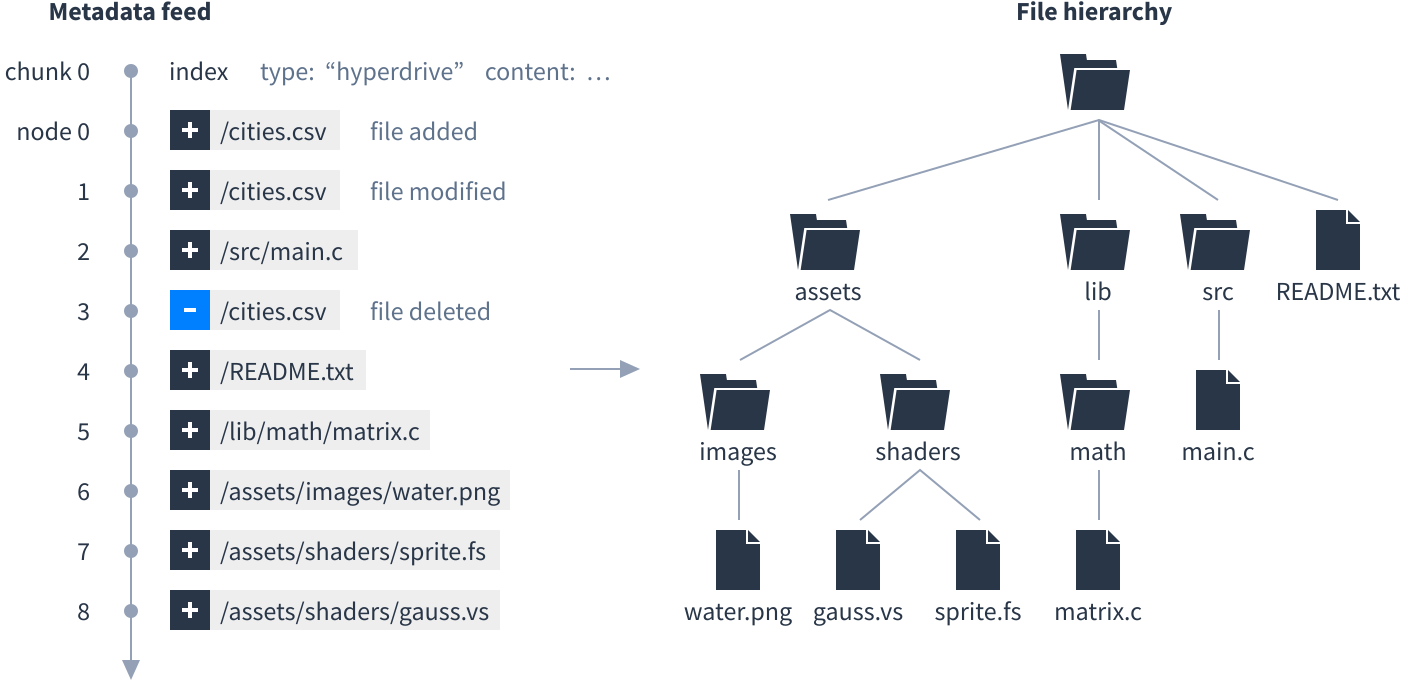
For each file in the hierarchy, find the most recent entry for it in the metadata feed and remember the node number. For each folder, remember the highest node number among its children:
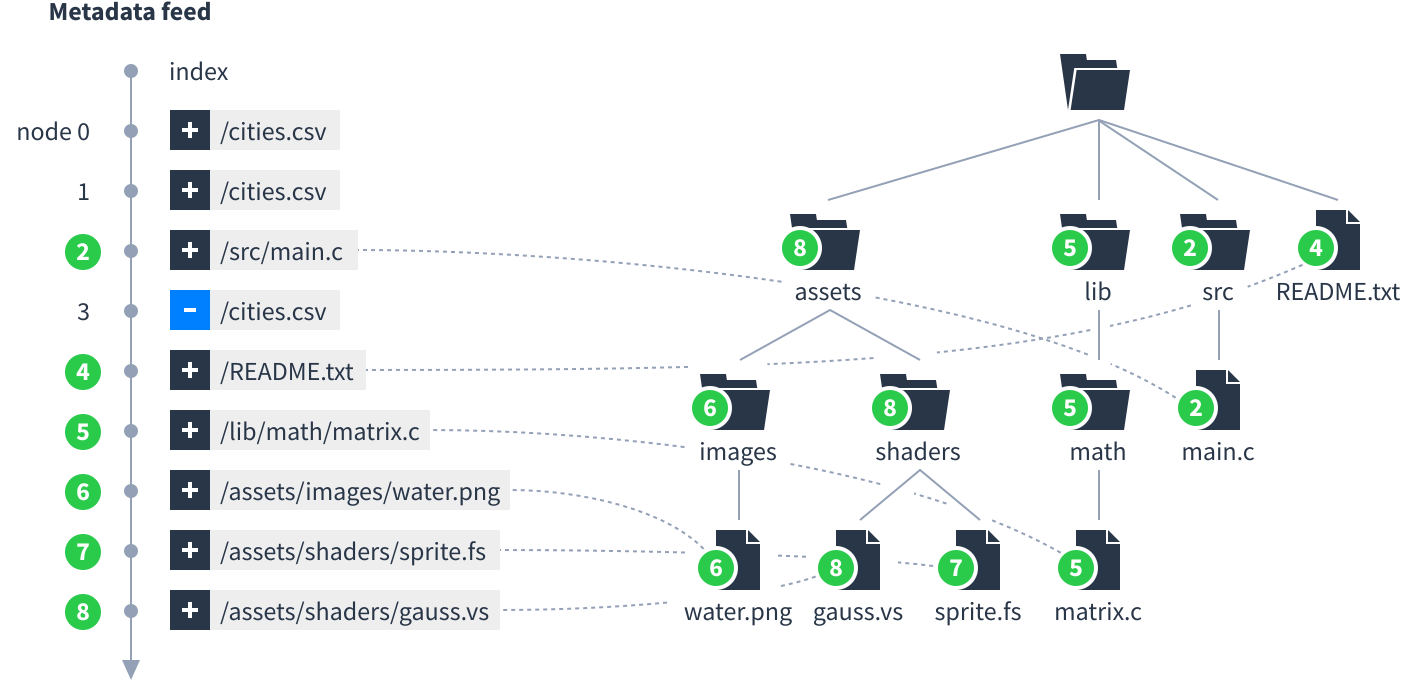
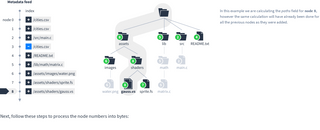
Locate the file that was just added. Select that file and all its parent folders up to the root folder. Also select files and folders within those folders, but not their descendants. Ignore everything else.
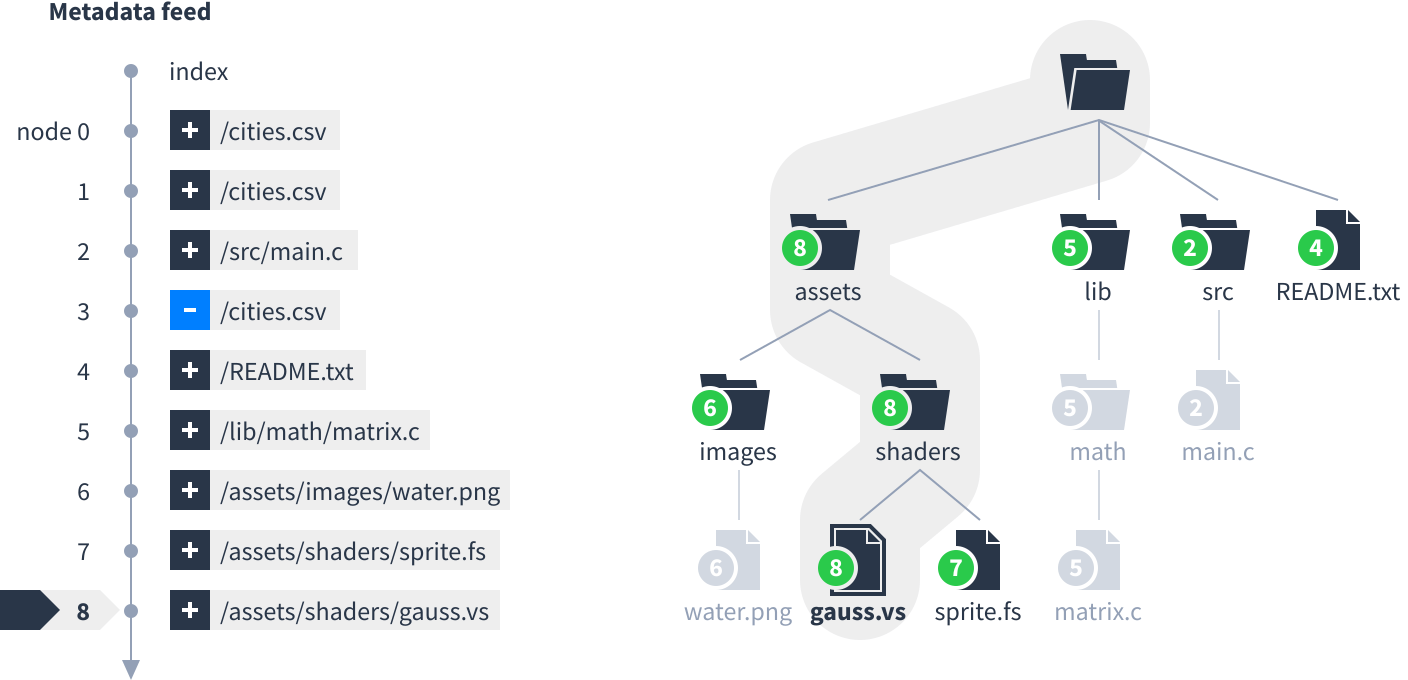
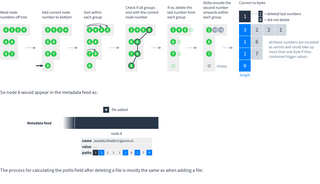
Next, follow these steps to process the node numbers into bytes:
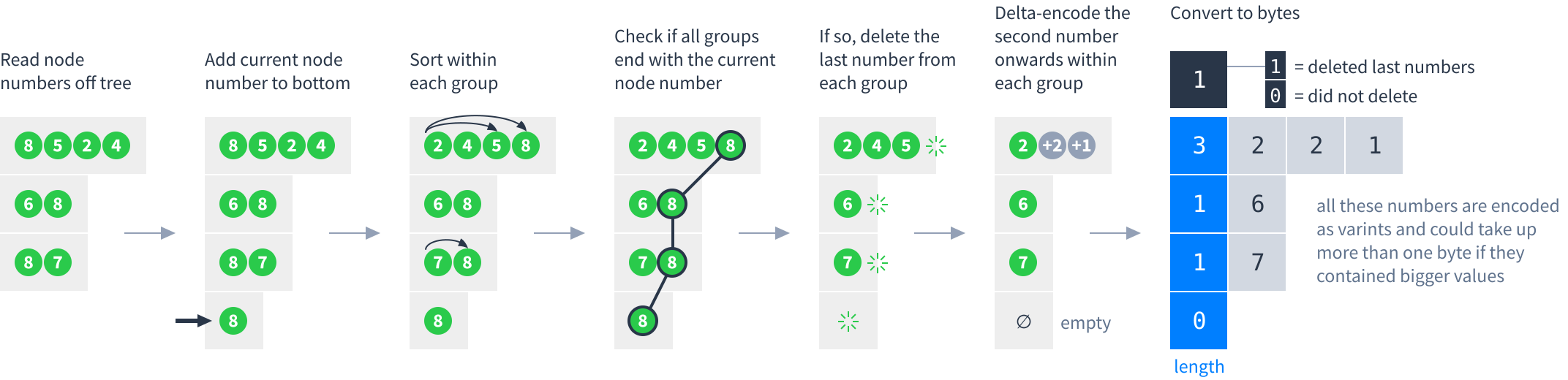
So node 8 would appear in the metadata feed as:

The process for calculating the paths field after deleting a file is mostly the same as when adding a file:
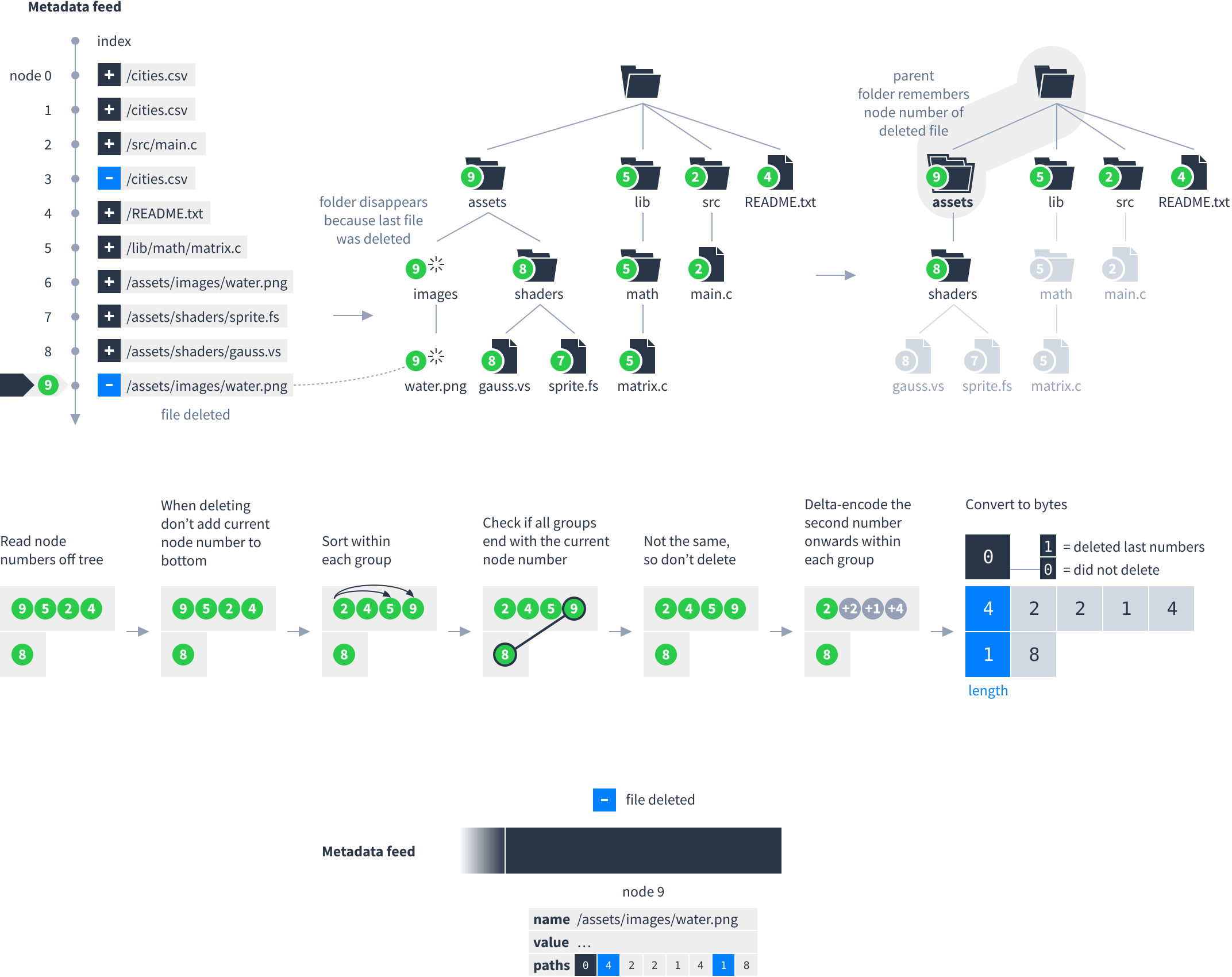
Future of Dat
Dat was first released in 2013, which in terms of internet infrastructure is very recent. Parts of the protocol are still changing today to enable Dat to handle bigger datasets, more hostile network conditions and support new types of applications.
This guide has described the Dat protocol as of January 2019. Here’s a brief summary of upcoming proposals to modify the Dat protocol in the near future:
-
Hyperdrive is the technical name of the files and folders system. Hyperdrive is going to be completely overhauled to make it faster for datasets containing millions of files. The new version will use a data structure called a prefix tree. There will also be refactoring changes so that files/folders and key/value databases use the same underlying storage system.
-
Hyperswarm is a new set of discovery mechanisms for finding other peers. It will replace the local network discovery and centralized DNS discovery mechanisms. It will also replace the BitTorrent distributed hash table mechanism that is in use today (but not documented in this guide).
Hyperswarm is able to hole-punch through NAT devices on networks. This helps users on residential or mobile internet connections directly connect to each other despite not having dedicated IP addresses or being able to accept incoming TCP connections.
-
Multi-writer will allow Dats to be modified by multiple devices and multiple authors at the same time. Each author will have their own secret key and publish a Dat with their data in it. Multi-writer fuses all of these separate Dats into one “meta-Dat” that is a view of everyone’s data combined.
-
NOISE protocol is a cryptographic framework for setting up secure connections between computers on the internet. This will replace how handshakes and encryption currently work in the wire protocol.
NOISE will fix weaknesses such as connections being readable by any eavesdropper who knows the Dat’s public key. It will allow connections to be authenticated to prevent tampering and also support forward secrecy so that past connections cannot be decrypted if the key is later stolen.
This is the end of How Dat Works. We’ve seen all the steps necessary to download and share files using Dat. If you’d like to write an implementation then check out the Dat Protocol Book which offers guidance about implementation details.
The focus of this guide has been on storing files, but this is just one use of Dat. The protocol is flexible enough to store arbitrary data that does not use the concept of files or folders. One example is Hyperdb which is a key/value database, but Dat can be extended to support completely different use cases too. Take a look at the formal protocol specifications for more information.
Visual index